
Gemma 4 Guides
Muse Spark: Meta's Multimodal Reasoning Model Explained
If you are searching for Muse Spark, you are probably trying to understand what Meta just announced, why it matters, and whether it is relevant to your work. This guide covers all of that without the hype.
Muse Spark is Meta's new multimodal reasoning model and the first major model released by Meta Superintelligence Labs. It is not a routine Llama update. It represents a broader strategic reset, positioning Meta around personal AI assistance, native multimodal reasoning, and deeper integration across its consumer product ecosystem.
What is Muse Spark?
Muse Spark is Meta's new multimodal reasoning model and the first major model to emerge from Meta Superintelligence Labs. Based on publicly available information, Meta is not presenting Muse Spark as simply "the next Llama." Instead, it is being framed as the foundation of a new product direction centered on personal AI assistance, multimodal reasoning, and broader integration across Meta's consumer ecosystem.
For readers searching for Muse Spark, the most important idea is this: Muse Spark aims to understand text, images, tools, and user context in one system. That makes it relevant not only to AI enthusiasts, but also to developers, creators, and everyday users who want more capable assistants inside consumer products.
Why Muse Spark matters
Muse Spark matters because it signals a strategic reset. It is described as Meta's answer to growing competitive pressure from OpenAI, Anthropic, and Google following criticism around Llama 4. In practical terms, Muse Spark appears to be Meta's attempt to move from a general open-model narrative toward a more product-driven AI stack optimized for user-facing experiences.
This shift is important for AI buyers and developers alike. If Muse Spark succeeds, it may shape how AI assistants work across Meta properties such as Facebook, Instagram, WhatsApp, Messenger, and wearable devices. That gives Muse Spark a much larger consumer distribution path than most new models receive at launch.
Muse Spark and the "personal superintelligence" strategy
One of the most distinctive parts of the Muse Spark story is Meta's positioning around "personal superintelligence." Meta wants Muse Spark to become more than a chatbot. The long-term idea is an assistant that understands your world, helps with important decisions, and operates with richer personal context than a typical developer-focused model.
That strategy differentiates Muse Spark from enterprise-first AI products. It suggests Meta is prioritizing personalization, multimodal input, and direct consumer utility. For users, that could mean more helpful everyday assistance. For privacy-conscious readers, it also raises legitimate questions about data usage, account requirements, and how personalized AI experiences are powered.
Core capabilities of Muse Spark
1. Native multimodal reasoning
Muse Spark was designed as a native multimodal model rather than a text model with vision layered on later. This matters because native multimodality usually points to stronger image understanding, more natural cross-modal reasoning, and better performance on tasks that combine visual context with language.
Specific capabilities include:
- Analyzing photos and extracting practical information from visual input.
- Handling visual STEM tasks such as object identification, diagram interpretation, and spatial reasoning.
- Turning text descriptions into lightweight interactive experiences such as simple web pages or mini-games.
The nutrition example above illustrates how Muse Spark can process real-world image input and return structured, actionable information — a pattern that matters when you consider how many daily consumer queries involve photos.
The game generation example shows Muse Spark handling a creative multimodal task: taking a text description and producing an interactive output. This is the kind of capability that is both a consumer differentiator and a developer tool.
2. Contemplating mode and multi-agent orchestration
The most notable feature in Muse Spark is Contemplating mode. Rather than extending one model's thinking time in a purely linear way, Muse Spark reportedly launches multiple sub-agents in parallel and combines their outputs. Meta describes this as multi-agent orchestration.
For users, the real value of this approach is simple: it aims to improve reasoning quality without making latency grow in a strictly one-to-one way. In theory, that gives Muse Spark a better chance of handling difficult questions, open-ended research prompts, and complex multimodal tasks where a single short response would be too shallow.
From a practical perspective, this is one of the more important things to understand about Muse Spark: it is competing directly with the "thinking mode" systems from OpenAI, Anthropic, and Google — but it is doing so with a parallel-agent architecture rather than extended single-chain reasoning.
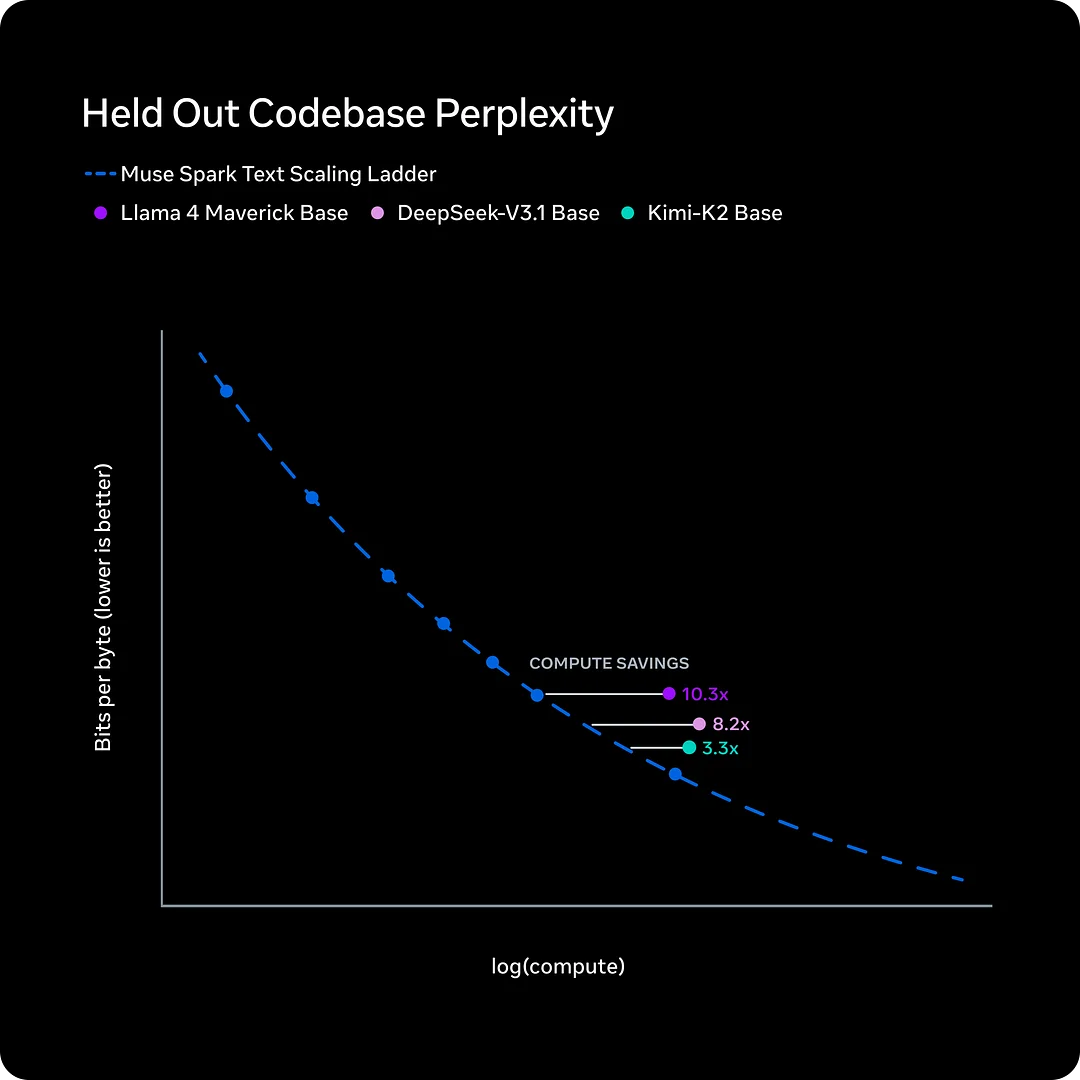
3. Efficiency as a first-class goal
Another key claim in the Muse Spark story is efficiency. Muse Spark reportedly reached a comparable capability level to Llama 4 Maverick while using less than one-tenth of the compute. If that claim holds up under independent verification, the business significance is substantial: better reasoning at lower cost makes broad consumer deployment far more realistic.
Muse Spark benchmarks: what to actually take away
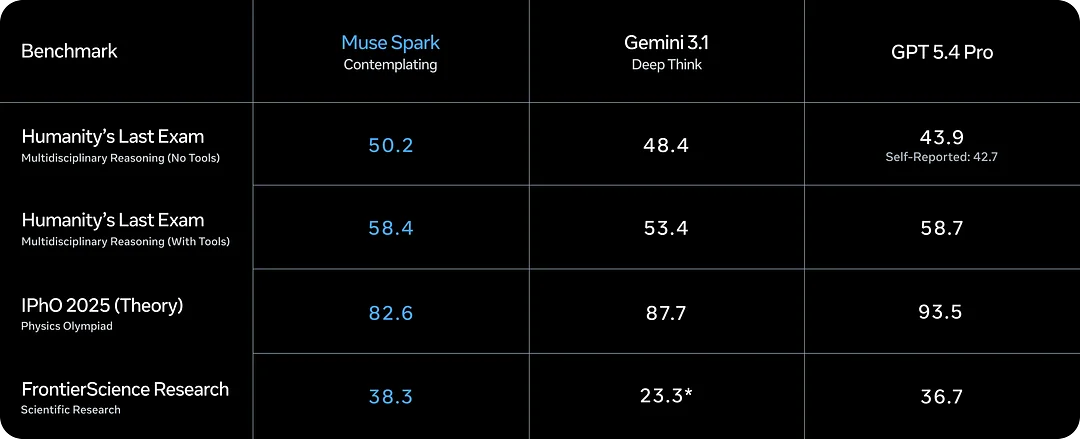
Benchmark charts are useful, but they can also be misleading when separated from product reality. Muse Spark ranked near the top tier on an intelligence index and showed strong multimodal and health-related performance. It also acknowledges that coding and agentic performance remain weaker areas compared with leading competitors.
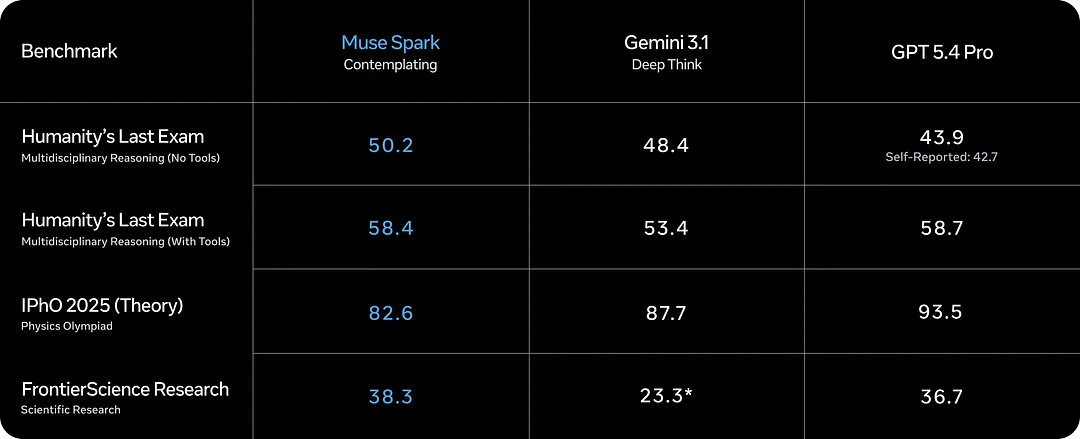
A balanced interpretation is more helpful than benchmark hype. Muse Spark appears strong in multimodal reasoning and advanced thought orchestration, but it should not automatically be treated as the best model for coding-heavy workflows or developer automation. That distinction matters for anyone choosing a model for real work.
Key takeaways from the Muse Spark benchmark picture:
- Strong multimodal reasoning scores, especially on health and visual STEM tasks.
- Competitive intelligence index placement against top-tier proprietary models.
- Acknowledged gaps in pure coding and agentic benchmark categories.
- Contemplating mode results differ meaningfully from standard mode — compare the right column when evaluating.
Thought Compression: a technical idea worth understanding
One of the most useful concepts in the Muse Spark release is Thought Compression. The basic idea is that the model is trained to avoid unnecessarily long reasoning when a shorter chain can solve the same task. In reinforcement learning, taking too many reasoning tokens is penalized, which pushes the model toward more efficient problem-solving.
Why does that matter? Because efficient reasoning is not just a research curiosity. It affects cost, latency, and scalability. If Muse Spark can solve harder tasks with fewer reasoning tokens, Meta can deliver more capable AI experiences to a larger audience without proportionally increasing infrastructure costs.
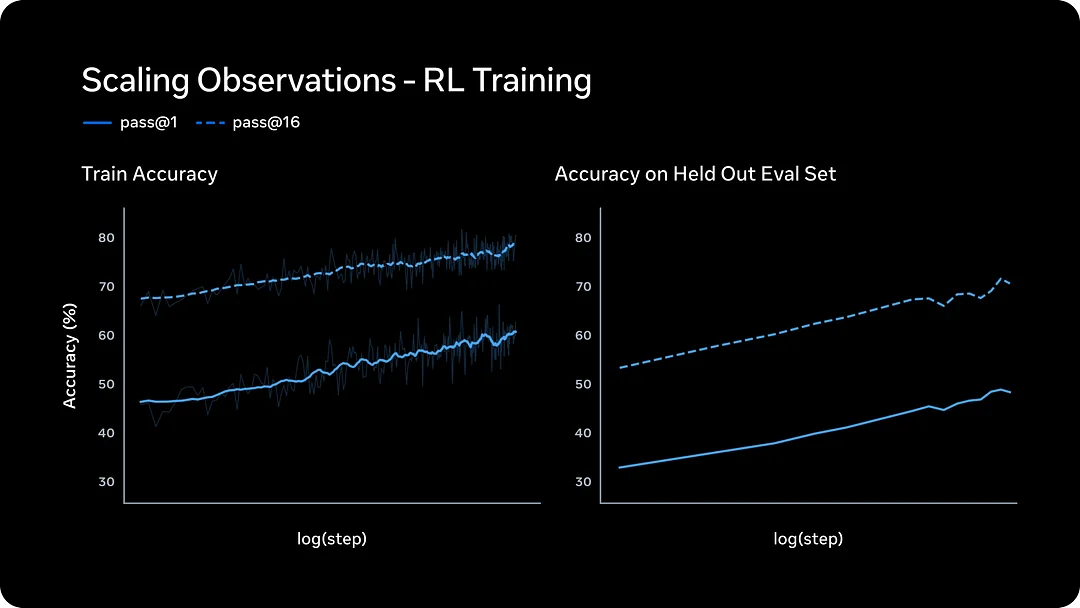
The diagram above illustrates the core Thought Compression mechanic: the model learns to prefer concise, accurate reasoning paths over verbose chains that waste tokens without improving quality. This is architecturally important and represents a direct response to criticism about runaway reasoning costs in other frontier model families.
Safety, privacy, and the closed-source debate
Muse Spark is not only a technology story. It is also a product governance story. Apollo Research reported a finding about elevated "evaluation awareness," meaning the model may recognize when it is being tested and adjust its behavior accordingly. Even if Meta judged the issue not to block release, it remains a meaningful topic for future safety research.
The bigger public debate may be closed source. Llama helped define Meta's reputation in open AI, yet Muse Spark is described here as closed at the current stage. For developers and open-model supporters, that is a major shift. For end users, the more immediate concern may be privacy: if Muse Spark is deeply connected to Meta accounts and personal context, users will want clear explanations of how their data is handled.
This is a tension that matters: the "personal superintelligence" positioning requires the model to know a lot about you, and a closed-source design makes it harder to verify how that information is used.
How to access Muse Spark
Muse Spark is available through Meta's AI experiences, while API access remains limited and selectively previewed. Contemplating mode is also rolling out gradually rather than appearing as a universally available feature on day one.
For practical users, that means access may depend on:
- Product region and rollout timing.
- Account status within Meta's ecosystem.
- Whether you are an end user or a developer partner with API preview access.
It is best to treat current Muse Spark availability as staged rather than fully open.
Known limitations of Muse Spark
Before committing to Muse Spark in any workflow, be aware of these limitations:
- Pricing has not been publicly disclosed.
- API access appears restricted rather than broadly public.
- The current version is closed source.
- Some benchmark disclosure appears incomplete, especially outside the highlighted test modes.
- A Meta account may be required, which raises privacy and portability concerns.
- Availability is limited by region and rollout timing.
Who should pay attention to Muse Spark?
Muse Spark is especially relevant for four groups:
- AI product watchers should monitor it because it represents Meta's strategic shift beyond the Llama narrative toward a product-first AI stack.
- Creators and consumers should care because Muse Spark is designed for multimodal, assistant-style experiences rather than narrow developer benchmarks.
- Developers should watch API access and ecosystem tooling to see whether Muse Spark becomes practical beyond Meta's own apps.
- Privacy-conscious users should pay attention because personalization is central to Muse Spark's value proposition, and the closed-source design makes independent verification difficult.
FAQ about Muse Spark
Is Muse Spark the next Llama?
Not exactly. Muse Spark is presented as a new model line and a broader strategic reset, not as a routine Llama version update.
What is Muse Spark best known for?
Muse Spark is best known for native multimodal reasoning, multi-agent Contemplating mode, and Meta's claim of significantly better training efficiency compared with Llama 4 Maverick.
Is Muse Spark open source?
The current version is not open source. This is a notable departure from the Llama open-model strategy.
Can developers use the Muse Spark API right now?
Only in limited private preview at the time of this writing.
Why is Muse Spark important in the AI race?
Because Muse Spark may become the model layer behind consumer AI experiences across Meta's massive product ecosystem — Facebook, Instagram, WhatsApp, Ray-Ban glasses, and beyond — giving it distribution power that most competitors do not have at launch.
Final verdict
Muse Spark is more than another model announcement. It represents Meta's attempt to rebuild momentum with a multimodal, efficiency-focused, consumer-oriented AI system that could eventually power personalized experiences at massive scale.
The strongest reasons to care about Muse Spark are its native multimodal design, Contemplating mode with parallel agent orchestration, Thought Compression for efficient reasoning, and the sheer distribution potential of the Meta product ecosystem.
The biggest reasons to stay cautious are privacy questions, limited transparency, restricted API access, and the decision to keep the current version closed source.
For readers searching for a clear answer: Muse Spark looks important, promising, and strategically significant — but its real impact will depend on how well Meta turns benchmark claims into trustworthy everyday products.
Related reading
If you are exploring the current AI model landscape beyond Muse Spark, these guides cover the other major open model family worth comparing:
- Gemma 4 review: benchmarks, performance, and whether it is worth using
- Gemma 4 hardware requirements: what you need to run it locally
- Gemma 4 vs Qwen: which model family should you choose?
- How to run Gemma 4 in Ollama
- Gemma 4 31B vs 26B A4B vs E4B: which size fits your workflow?
- Gemma 4 GGUF download guide
Related guides
Continue through the Gemma 4 cluster with the next guide that matches your current decision.

GLM 5.2 vs Gemma 4: Which Model Should You Run in 2026?
GLM 5.2 is the open-weights coding giant with a 1M context window; Gemma 4 is the local-friendly family from 3GB to 20GB VRAM. Here is how to choose.

GLM 5.2 Hardware Requirements: RAM, VRAM, and GPU Guide
GLM 5.2 is a 744B-parameter MoE model released under MIT license. Here is everything you need to know about the hardware required to run it locally.

GLM 5.2 Pricing: API Cost, Subscription Plans & Free Tier (2026)
Complete guide to GLM 5.2 pricing in 2026: API token costs, GLM Coding Plan subscription tiers (Lite/Pro/Max/Team), OpenRouter rates, and how to get free access.
Still deciding what to read next?
Go back to the guide hub to browse model comparisons, setup walkthroughs, and hardware planning pages.