
Gemma 4 指南
Kimi K2.6 评测:Benchmark、API,以及 K2.7 Code 更新

Kimi K2.6 评测:Benchmark、价格、API,以及它值不值得用
Moonshot AI 在 2026 年 4 月 20 日发布了 Kimi K2.6,当时明确定位为 coding 与 agent 场景的主力 open-weight 模型。到 2026 年 6 月,Kimi 线已经继续推进,平台上出现了面向 coding 的 K2.7 Code。K2.6 仍然重要,因为它把这条线推向了 可持续的长时自主执行能力,而不只是 benchmark 分数。
这篇评测主要回答三个问题:K2.6 到底是什么、它真正擅长什么、以及你今天是否应该认真试试它。
2026 年 6 月更新: Kimi 平台现在已经列出 K2.7 Code,并将其定位为更强的代码模型。请把 K2.6 理解为 2026 年 4 月的重要发布和既有集成目标;如果你今天新做 coding-agent 评估,应把 K2.7 Code 一起纳入。

快速结论
- 发布时间: 2026 年 4 月 20 日
- 可用渠道:
kimi.com、Kimi App、Moonshot API、Kimi Code CLI。开放权重在 Hugging Face 的moonshotai/Kimi-K2.6 - 架构: Mixture-of-Experts,总参数约 1T,每个 token 激活约 32B,256K 上下文窗口,基于 MoonViT 的原生图像/视频能力,Modified MIT 许可
- 特别强的方向: 长时 coding、agent 工具调用、多 agent 协同(Agent Swarm)、从 prompt 直接生成前端
- 不那么适合的方向: 纯数学竞赛型推理、极低延迟短对话、以及比起峰值能力更看重成本可预测性的工作负载
- 结论: 如果你已经围绕 K2.6 集成,它仍然值得认真对待;如果你现在新做 coding-agent 评估,应把 K2.7 Code 放在一起测试。
Kimi K2.6 到底是什么
按照 Moonshot 自己的说法,Kimi K2.6 是一个 开源、原生多模态、面向 agent 的模型,重点推进四种能力:长时 coding、由代码驱动的设计、主动式自主执行,以及 swarm 式任务编排。
它的技术轮廓如下:
- 1 万亿 总参数、每个 token 320 亿 激活参数(MoE)
- 256K 上下文窗口(在 API 价格页中精确写作 262,144 tokens)
- 384 个 routed experts,每个 token 激活 8 个 + 1 个共享专家
- 沿用并增强了 K2.5 的 MoonViT 4 亿参数视觉编码器
- 支持 文本、图像、视频 输入(视频在第三方部署中仍被标记为实验性)
- 提供 Thinking 和 Instant 两种模式(默认开启 Thinking)
- Modified MIT 许可——对绝大多数用法都较宽松,但超大规模部署有可见 attribution 条款
换句话说,它首先是一个 coding / agent 模型,其次才是一个 chat 模型。无论从架构、功能排序还是宣传重点,方向都很一致。
从 K2.5 到 K2.6 变化了什么
K2.5 在 2026 年 1 月发布,K2.6 在 4 月发布,间隔不到三个月。对这个量级的模型来说,这个迭代节奏相当快。改进大致集中在三块。
长时 coding 的可靠性。 Moonshot 最爱展示的是“耐力”。例如,他们展示 K2.6 在 Mac 上用 Zig 自主优化 Qwen3.5-0.8B 的本地推理,持续了 12 小时以上、进行了 4,000+ 次工具调用,最后比 LM Studio 快了约 20%。另一组 demo 中,它对一个已经运行 8 年的开源金融撮合引擎 exchange-core 进行了 13 小时自主重构,据称中等吞吐提升约 185%。这些都是自报数据,更适合看作能力上限,而不是结果保证。但它们共同说明了一件事:K2.6 明显在“长时间做事不崩”这件事上下了功夫。
Agent Swarm 扩大。 如果 K2.5 大致是 100 个 sub-agent、1,500 步协调,那么 K2.6 的说法已经变成 300 个 sub-agent、4,000 步协调。K2.6 自己负责总协调,按 agent 技能画像派单、检测卡顿、在失败时重构子任务。Moonshot 还推出了 Claw Groups 作为研究预览,让不同设备、不同模型上的异构 agent 也能进入同一协作空间。
前端与基础全栈生成。 它所谓的 “coding-driven design” 不只是写页面,还包括从自然语言直接生成完整网站、调用图像和视频生成工具保证视觉一致性,以及处理注册、数据库操作、会话管理等基础 full-stack 工作。
指令遵循更强。 这点没有那么 flashy,但不少独立观察都提到:和 K2.5 相比,K2.6 在日常使用中更听指令了。
Kimi K2.6 的 benchmark 概览
以下数字全部来自 Moonshot 自身的评测。它们适合用来做方向判断,但不能直接视为独立最终结论。
Agent 类
- Humanity's Last Exam (HLE-Full) with tools: 54.0
- BrowseComp: 83.2
- DeepSearchQA (F1): 92.5
- Toolathlon: 50.0
Coding 类
- SWE-Bench Pro: 58.6
- SWE-Bench Verified: 80.2
- SWE-Bench Multilingual: 76.7
- LiveCodeBench v6: 89.6
- Terminal-Bench 2.0: 66.7
Vision 类
- Charxiv with Python: 86.7
- Math Vision with Python: 93.2
- V*: 96.9
比较合理的读法是:K2.6 在 coding 与 agent benchmark 上,确实已经能和前沿闭源模型正面竞争。但在 AIME 式数学或 GPQA-Diamond 这种纯 reasoning 基准上,更偏 reasoning 训练的模型依然可能更强。agent benchmark 对 harness、工具可用性、上下文管理方式非常敏感,因此独立排行榜出现不同分数并不奇怪。
Kimi K2.6 做 coding 到底有多强
它比较适合的场景:
- 复杂多步 coding,包括读代码库、规划修改、跨文件编辑、跑测试和反复迭代
- 从自然语言或视觉输入直接做 前端生成
- 在 Claude Code、Codex、OpenCode、OpenClaw、Kimi Code 等 CLI 中做 agentic coding
- 把中等规模代码库整块塞进 256K 窗口的 长上下文任务
- 非英文注释和文档,尤其是中文
不太适合的场景:
- 一个更轻、更便宜的模型就能完成的 简单补全
- 需要严格可预测固定成本 的 workload
- 极低延迟聊天。Thinking 模式默认开启,会给每次响应都加上 reasoning token 开销与时延
快速适配判断:
| 工作负载 | K2.6 适配度 |
|---|---|
| 数小时自主 coding agent | 非常强 |
| Copilot 风格自动补全 | 过度配置 |
| 从 mockup 到可运行 UI | 很强 |
| 长文档分析 | 很强 |
| 实时聊天 widget | 偏弱(延迟) |
| 数学竞赛题求解 | 不错,但不是最强 |
| 大量重复 prompt 的数据流程 | 非常强(缓存) |
API、价格与部署方式
K2.6 通过多个渠道提供,每条路径都有不同的取舍。
Moonshot API。 地址是 https://api.moonshot.ai/v1,OpenAI 兼容。Kimi 全球价格页现在列出:K2.6 为 cache hit $0.16 / MTok、input $0.95 / MTok、output $4.00 / MTok;K2.7 Code 为 cache hit $0.19 / MTok、input $0.95 / MTok、output $4.00 / MTok。如果你的账号使用中国区/人民币控制台,请以本地账单页为准。速率限制和网页搜索等工具费用会随账号和平台政策变化,生产估算前请查看实时平台页面。
Hugging Face。 开放权重在 moonshotai/Kimi-K2.6,许可为 Modified MIT。官方部署指南推荐 vLLM、SGLang、KTransformers。model card 还包含多模态输入、工具调用以及如何保留 reasoning_content。
Ollama。 官方库条目 kimi-k2.6:cloud 是云路由模型,不是本地权重。
Kimi Code。 Moonshot 自家的终端 coding agent。
kimi.com 与 Kimi App。 面向普通用户的 chat / agent 入口,拥有独立的免费和付费层级。
对大多数团队来说,选择通常很直接:生产用 Moonshot API,快速试用用 Ollama Cloud,认真自托管就走 Hugging Face + vLLM / SGLang。
谁应该用 Kimi K2.6
- Agent 开发者。 如果你的产品要串联数百次工具调用,K2.6 就是为这种形状的工作流设计的。
- Coding 工具用户。 Claude Code、Codex、OpenCode、OpenClaw、Kimi Code 都有一等支持。
- Vision-to-code 工作流。 MoonViT 让 screenshot-to-code 这类任务不再需要额外接一个视觉模型。
- 长文档流水线团队。 256K 上下文 + 激进缓存,使 RAG 和整库分析更划算。
- 中文或双语团队。 Kimi 在中文能力上的优势仍然很真实。
谁可以跳过它
- 只追求 API token 最低价的团队。K2.6/K2.7 Code 的 cache-hit 价格有竞争力,但它们并不自动等于短问答最便宜选项。
- 需要文本型固定成本、预算高度可预测的产品
- 必须严格区分云端与本地,但又没有 self-host 预算的场景
- 没有时间精调 Thinking、tool calling 与 caching 的团队
最终结论
Kimi K2.6 是 2026 年最认真、最有分量的 open-weight 发布之一。按照 Moonshot 自己的数字,它在与自主工作流最相关的 coding 与 agent benchmark 上,已经可以和 GPT-5.4、Claude Opus 4.6 打正面,甚至部分领先;同时它仍然保持 open-weight 和较宽松的许可证。长时 demo 也足够具体,让人更容易相信它不是只为 benchmark 调过。
当然,保留意见也很明确:这些比较都是自报,独立 harness 会让数字移动,而 12 小时任务的日常稳定性最终还是看你的具体任务。价格不算差,但它更奖励认真设计 prompt 与缓存策略的团队,而不是随便拿来就用。
如果你在 2026 年围绕 coding agent 或长时自主工作流构建产品,K2.6 值得认真评估,但它已经不应是唯一的 Kimi benchmark。coding-first 工作负载请把 K2.7 Code 一起测,再比较 cost-per-task 和可靠性。接下来可以读一下 API 价格指南、Ollama 指南 以及 self-host 用的 Hugging Face 指南。
FAQ
Kimi K2.6 是什么?
Kimi K2.6 是 Moonshot AI 于 2026 年 4 月 20 日发布的 open-weight、原生多模态、面向 agent 的模型。它是一个约 1T 参数的 MoE 模型,每个 token 激活约 32B,拥有 256K 上下文和原生文本/图像/视频输入能力。
Kimi K2.6 适合 coding 吗?
按 Moonshot 公布的 benchmark 看,适合:SWE-Bench Pro 58.6、SWE-Bench Verified 80.2、LiveCodeBench v6 89.6。它在多步骤、多文件、agent loop 的 coding 场景尤其强。对简单补全来说则偏重。
它支持图像和视频吗?
支持。图像输入广泛可用;视频输入在 Moonshot 官方 API 上可用,在第三方部署中被标记为实验性。
它有 API 吗?
有,地址是 https://api.moonshot.ai/v1,与 OpenAI 兼容。你只需替换 SDK 的 base URL 和 key 即可。
Kimi K2.6 多少钱?
Kimi 全球价格页显示:K2.6 为 cache hit $0.16 / MTok、input $0.95 / MTok、output $4.00 / MTok;K2.7 Code 为 cache hit $0.19 / MTok、input $0.95 / MTok、output $4.00 / MTok。工具费用和速率限制请查看实时控制台。
可以在 Ollama 里用吗?
可以,通过官方模型库中的 kimi-k2.6:cloud。不过它是云模型,不是本地模型。
Kimi K2.6 是开源的吗?
权重已在 Hugging Face 以 Modified MIT 许可发布。对绝大多数团队来说,这个许可基本可以视为宽松可用,只是在超大规模部署时有 attribution 要求。
相关阅读
继续沿着 Gemma 4 内容集群往下读,选一个离你当前决策最近的下一篇。

Kimi K3 详解:Moonshot AI 的 2.8T Open-Weight 模型
Moonshot AI 的 Kimi K3 于 2026 年 7 月 16 日发布,是一个 2.8 万亿参数的 open-weight 模型,在多项 benchmark 上超过 Claude Opus 4.8。本文说明它到底是什么、还缺什么,以及今天如何试用。
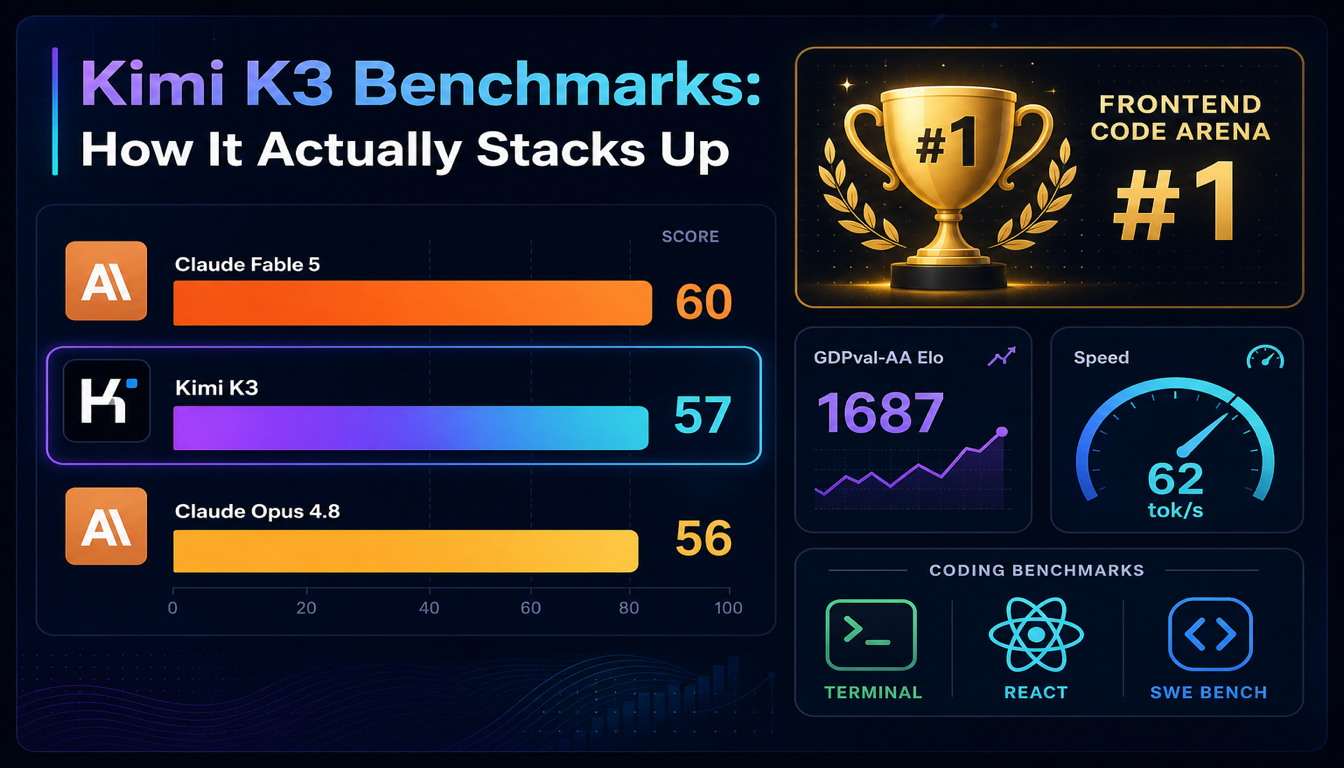
Kimi K3 Benchmark:实际表现如何
Kimi K3 发布不到一天就登顶 LMArena 的 Frontend Code Arena,并在 Artificial Analysis Intelligence Index 上超过 Claude Opus 4.8。以下是数字实际说明了什么——以及它们没讲全的地方。

Kimi K2.6 API Key 与价格:已补充 K2.7 Code
Kimi K2.6 与 K2.7 Code 的当前 API 价格、cache hit 的含义、速率限制层级如何影响吞吐,以及做预算前应该核对哪些项目。
还没决定下一篇看什么?
回到指南页,按模型对比、本地部署和硬件规划三个方向继续浏览。