
Hướng dẫn Gemma 4
Đánh Giá Kimi K2.6: Benchmark, Giá, API và Có Đáng Dùng Không

Cập nhật ngày 14 tháng 6 năm 2026: Kimi hiện đã có K2.7 Code là mô hình coding mới hơn. Giá toàn cầu: K2.6 $0.16 cache hit / $0.95 input / $4.00 output mỗi MTok; K2.7 Code $0.19 / $0.95 / $4.00. Hãy kiểm tra billing theo khu vực, rate limit và giá công cụ trong console trực tiếp.
Đánh Giá Kimi K2.6: Benchmark, Giá, API và Có Đáng Dùng Không
Moonshot AI đã phát hành Kimi K2.6 vào ngày 20 tháng 4 năm 2026 — model open-weight mạnh nhất của họ cho tới nay, được định vị như một cỗ máy coding và agent. Chưa đầy hai tháng trước đó, K2.5 đã đứng đầu trong nhóm open-weight về long-context reasoning. K2.6 đẩy quỹ đạo đó đi tiếp, nhưng theo một hướng rất cụ thể: không chỉ là thắng benchmark, mà là duy trì khả năng thực thi tự động trong thời gian dài.
Bài review này trả lời ba câu hỏi: K2.6 thực chất là gì, nó thực sự giỏi ở đâu, và bạn có nên thử nó ngay bây giờ hay không.

Câu trả lời nhanh
- Ngày phát hành: 20 tháng 4 năm 2026.
- Có mặt trên:
kimi.com, ứng dụng Kimi, API Moonshot, Kimi Code CLI. Weights mở trên Hugging Face tạimoonshotai/Kimi-K2.6. - Kiến trúc: Mixture-of-Experts, khoảng 1T tham số tổng, khoảng 32B tham số hoạt hóa mỗi token, context window 256K, vision/video gốc qua encoder MoonViT, giấy phép Modified MIT.
- Mạnh nhất ở: coding dài hơi, tool use kiểu agent, điều phối đa agent (“Agent Swarm”), và sinh front-end từ prompt.
- Không phải lựa chọn tốt nhất cho: toán thi đấu thuần reasoning, chat cực ngắn cần độ trễ cực thấp, hoặc workflow mà tính ổn định của chi phí quan trọng hơn khả năng cực đại.
- Kết luận: nếu bạn xây coding agent hoặc workflow tự động chạy dài, K2.6 xứng đáng được đánh giá nghiêm túc. Nếu bạn chỉ cần một model chat rẻ, nó là quá tay.
Kimi K2.6 thực sự là gì
Theo cách Moonshot tự mô tả, Kimi K2.6 là một model open-source, đa phương thức gốc và agentic, được đẩy mạnh theo bốn hướng: coding dài hạn, design được dẫn bằng code, tự động thực thi chủ động và điều phối nhiệm vụ kiểu swarm.
Hình dạng kỹ thuật:
- 1 nghìn tỷ tham số tổng, 32 tỷ tham số hoạt hóa trên mỗi token (MoE).
- 256K context window (chính xác 262,144 tokens trên trang giá API).
- 384 experts được route, với 8 experts hoạt động + 1 expert dùng chung trên mỗi token.
- MoonViT vision encoder 400M tham số từ K2.5, nay được huấn luyện cải thiện thêm.
- Input text, image, video (video được đánh dấu experimental trên các triển khai bên thứ ba).
- Thinking mode và Instant mode (Thinking là mặc định).
- Giấy phép Modified MIT — gần như thoải mái cho đa số use case, với điều khoản attribution khi triển khai ở quy mô rất lớn.
Đây là một model coding và agent trước hết, chat model sau đó. Kiến trúc, tính năng và tài liệu truyền thông đều cho thấy cùng một hướng.
Điều gì thay đổi từ K2.5 sang K2.6
Khoảng cách giữa K2.5 (tháng 1/2026) và K2.6 (tháng 4/2026) là chưa đến ba tháng. Với một model cỡ này, đó là chu kỳ lặp rất nhanh. Các cải tiến tập trung vào ba cụm.
Độ tin cậy của coding dài hạn. Demo nổi bật nhất của Moonshot nói về độ bền: K2.6 tự tối ưu hóa local inference của Qwen3.5-0.8B trên Mac bằng Zig suốt hơn 12 giờ và 4,000+ tool calls, kết quả nhanh hơn LM Studio khoảng 20%. Một demo khác cho thấy K2.6 refactor exchange-core, một open-source financial matching engine đã 8 năm tuổi, trong 13 giờ với khoảng 185% tăng throughput trung bình. Đây đều là số liệu tự công bố, nên hãy xem là trần năng lực chứ không phải cam kết. Nhưng nó cho thấy rõ ràng rằng điểm được cải thiện chính là khả năng bám nhiệm vụ dài hơi.
Agent Swarm được mở rộng. Nếu K2.5 phối hợp khoảng 100 sub-agent trong 1,500 bước, thì K2.6 được mô tả là mở rộng lên 300 sub-agent trong 4,000 bước phối hợp. K2.6 đóng vai trò coordinator, giao việc theo hồ sơ kỹ năng, phát hiện chỗ kẹt và tái sinh subtasks khi thất bại. Moonshot cũng giới thiệu Claw Groups như một research preview cho phép các agent dị loại từ nhiều thiết bị và model khác nhau tham gia vào cùng một không gian tác chiến.
Sinh front-end và full-stack cơ bản. Câu chuyện “coding-driven design” của K2.6 bao gồm tạo website hoàn chỉnh từ prompt ngôn ngữ tự nhiên, kéo thêm công cụ sinh ảnh/video để giữ hình ảnh nhất quán, và xử lý những tác vụ full-stack cơ bản như signup, thao tác database hay session.
Instruction following tốt hơn. Kém hào nhoáng hơn nhưng quan trọng trong thực tế, nhiều reviewer độc lập đều ghi nhận K2.6 bám chỉ dẫn tốt hơn K2.5.
Snapshot benchmark của Kimi K2.6
Tất cả các số dưới đây đều đến từ báo cáo của Moonshot. Chúng hữu ích để định vị, nhưng không phải phán quyết độc lập cuối cùng.
Agentic
- Humanity's Last Exam (HLE-Full) with tools: 54.0
- BrowseComp: 83.2
- DeepSearchQA (F1): 92.5
- Toolathlon: 50.0
Coding
- SWE-Bench Pro: 58.6
- SWE-Bench Verified: 80.2
- SWE-Bench Multilingual: 76.7
- LiveCodeBench v6: 89.6
- Terminal-Bench 2.0: 66.7
Vision
- Charxiv với Python: 86.7
- Math Vision với Python: 93.2
- V*: 96.9
Cách đọc hợp lý là: K2.6 thực sự cạnh tranh với các model frontier closed-source trên benchmark coding và agent. Nó vẫn có thể kém hơn ở các benchmark reasoning thuần như AIME hay GPQA-Diamond, nơi những model được tối ưu reasoning nặng hơn vẫn nhỉnh hơn. Benchmark agent có thể thay đổi vài điểm chỉ vì harness khác nhau, nên bảng xếp hạng độc lập có thể cho kết quả hơi khác.
Kimi K2.6 tốt đến mức nào cho coding?
Những chỗ nó hợp:
- Coding nhiều bước phức tạp, bao gồm đọc codebase, lập kế hoạch thay đổi, chỉnh sửa qua nhiều file, chạy test và lặp lại.
- Sinh front-end từ prompt ngôn ngữ tự nhiên hoặc hình ảnh.
- Agentic coding qua CLI như Claude Code, Codex, OpenCode, OpenClaw và Kimi Code.
- Tác vụ long-context với codebase cỡ vừa nằm trong 256K.
- Tài liệu và comment không phải tiếng Anh, nhất là tiếng Trung.
Những chỗ nó kém phù hợp hơn:
- Hoàn thiện hàm đơn lẻ, nơi model nhỏ hơn, nhanh hơn, rẻ hơn là đủ.
- Workload cần chi phí cố định, dễ dự đoán.
- Chat độ trễ thấp. Thinking mode bật sẵn và làm tăng thời gian phản hồi.
Bảng fit nhanh:
| Workload | Độ hợp của K2.6 |
|---|---|
| Coding agent tự động chạy nhiều giờ | Rất mạnh |
| Autocomplete kiểu Copilot | Quá mức cần thiết |
| Mockup → UI chạy được | Mạnh |
| Phân tích tài liệu dài | Mạnh |
| Widget chat thời gian thực | Yếu (latency) |
| Giải toán thi đấu | Tốt nhưng không top |
| Pipeline có prompt lặp lại | Rất mạnh (cache) |
API, giá và các lựa chọn triển khai
K2.6 được phát hành qua nhiều kênh, mỗi kênh có đánh đổi riêng.
Moonshot API. Tương thích OpenAI tại https://api.moonshot.ai/v1. Giá global hiện tại: K2.6 có cached input $0.16 / 1M tokens, uncached input $0.95 / 1M, output $4.00 / 1M; K2.7 Code là $0.19 / $0.95 / $4.00. Rate limit phụ thuộc vào tài khoản và chính sách nền tảng hiện tại, nên hãy kiểm tra live console trước workload production. Web search tích hợp có thể bị tính phí riêng và cũng làm tăng input tokens ở request kế tiếp.
Hugging Face. Weights mở tại moonshotai/Kimi-K2.6 dưới giấy phép Modified MIT. Guide triển khai chính thức khuyến nghị vLLM, SGLang và KTransformers. Model card cũng giải thích cách xử lý multimodal input, tool calling và reasoning_content.
Ollama. Entry chính thức là kimi-k2.6:cloud — đây là model routed qua cloud chứ không phải local weights.
Kimi Code. Coding agent terminal của Moonshot, dùng K2.6 cho người đăng ký.
kimi.com và Kimi App. Bề mặt chat và agent cho người dùng phổ thông, với các tier miễn phí và trả phí riêng.
Với đa số team, cách chọn là: Moonshot API cho production, Ollama cloud để thử nhanh, Hugging Face + vLLM/SGLang cho self-hosting nghiêm túc.
Ai nên dùng Kimi K2.6
- Nhà phát triển agent. Nếu sản phẩm của bạn xâu chuỗi hàng trăm tool calls, K2.6 được xây đúng cho kiểu workload đó.
- Người dùng công cụ coding. Claude Code, Codex, OpenCode, OpenClaw và Kimi Code đều có đường tích hợp rõ ràng.
- Workflow vision-to-code. MoonViT giúp chuyển screenshot thành code mà không cần thêm model vision riêng.
- Team có pipeline tài liệu dài. Context 256K và cache mạnh giúp workflow kiểu RAG hay full-codebase trở nên kinh tế hơn.
- Team song ngữ hoặc thiên về tiếng Trung. Đây vẫn là điểm mạnh thực sự của Kimi.
Ai có thể bỏ qua
- Team chỉ tối ưu theo giá token API rẻ nhất.
- Sản phẩm cần chi phí cố định và dễ dự báo cho văn bản thuần.
- Workflow cần tách biệt nghiêm ngặt giữa cloud và on-prem nhưng không có ngân sách self-host.
- Team không có thời gian chỉnh Thinking mode, tool calling và caching.
Kết luận cuối
Kimi K2.6 là một trong những bản phát hành open-weight nghiêm túc nhất của năm 2026. Theo số liệu Moonshot công bố, nó cạnh tranh trực diện với GPT-5.4 và Claude Opus 4.6 ở các benchmark coding và agent quan trọng cho workflow tự động, đồng thời vẫn giữ open weights và giấy phép khá thoải mái. Các demo chạy dài cũng đủ cụ thể để tạo cảm giác rằng năng lực này không chỉ là benchmark tuning.
Những lưu ý thành thật: các so sánh đều là tự công bố, harness độc lập sẽ làm số thay đổi, và độ ổn định trong một nhiệm vụ dài 12 giờ còn phụ thuộc vào chính tác vụ đó. Giá cả hợp lý, nhưng K2.6 thưởng cho việc thiết kế prompt có chủ đích hơn là dùng bừa.
Nếu bạn đang xây quanh coding agent hoặc workflow tự động dài hơi trong năm 2026, K2.6 xứng đáng được đánh giá nghiêm túc. Các bước tiếp theo hợp lý là xem hướng dẫn giá API, hướng dẫn Ollama và hướng dẫn Hugging Face.
FAQ
Kimi K2.6 là gì?
Kimi K2.6 là model open-weight, đa phương thức gốc và agentic của Moonshot AI, phát hành ngày 20 tháng 4 năm 2026. Nó là một model MoE với khoảng 1T tham số tổng, khoảng 32B active parameters, context 256K và input text/image/video gốc.
Kimi K2.6 có tốt cho coding không?
Theo benchmark Moonshot công bố, có: SWE-Bench Pro 58.6, SWE-Bench Verified 80.2, LiveCodeBench v6 89.6. Nó đặc biệt mạnh ở các tác vụ nhiều bước, nhiều file và agent loop. Với autocomplete đơn giản thì hơi quá nặng.
Kimi K2.6 có hỗ trợ ảnh và video không?
Có. Ảnh được hỗ trợ rộng rãi. Video được hỗ trợ trên API chính thức của Moonshot và bị đánh dấu experimental trên các triển khai bên thứ ba.
Nó có API không?
Có, tại https://api.moonshot.ai/v1. API tương thích OpenAI, nên chỉ cần đổi base URL và key trong SDK.
Kimi K2.6 giá bao nhiêu?
Giá chính thức: cached input $0.16 / 1M tokens, uncached input $0.95 / 1M tokens, output $4.00 / 1M tokens. Web search tích hợp là giá công cụ hiện tại cho mỗi lần gọi cộng token của kết quả.
Có dùng được trong Ollama không?
Có, thông qua kimi-k2.6:cloud trong thư viện Ollama chính thức. Đây là model cloud, không phải local model.
Kimi K2.6 có phải open source không?
Weights được công bố trên Hugging Face dưới giấy phép Modified MIT. Với đa số team, giấy phép này gần như là permissive, chỉ có điều khoản attribution cho các triển khai cực lớn.
Hướng dẫn liên quan
Tiếp tục khám phá cụm nội dung Gemma 4 với bài hướng dẫn tiếp theo phù hợp với quyết định hiện tại của bạn.

Kimi K3: Giải Thích Mô Hình Open-Weight 2.8T Của Moonshot AI
Kimi K3 của Moonshot AI ra mắt ngày 16 tháng 7 năm 2026 với 2,8 nghìn tỷ tham số open-weight, vượt Claude Opus 4.8 trên nhiều benchmark. Đây là những gì nó thực sự là, còn thiếu gì và cách thử ngay hôm nay.
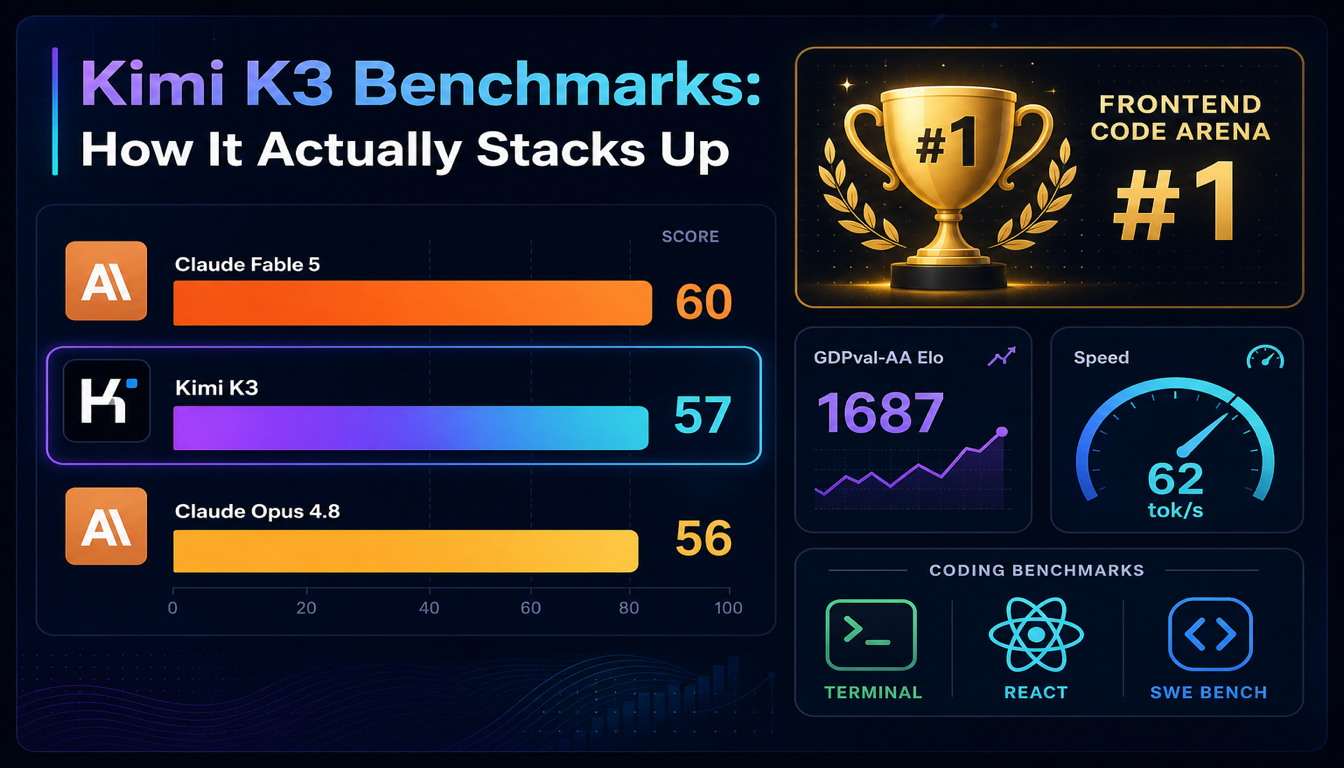
Benchmark Kimi K3: Thực Tế So Sánh Thế Nào
Kimi K3 đạt #1 trên LMArena Frontend Code Arena và vượt Claude Opus 4.8 trên Artificial Analysis Intelligence Index chỉ trong một ngày sau ra mắt. Đây là những gì các con số thực sự nói — và nơi chúng không kể hết câu chuyện.

API Key và Bảng Giá Kimi K2.6: Chi Phí Chính Thức, Rate Limit và Phí Tìm Kiếm Web
Mức giá token chính thức của Kimi K2.6, ý nghĩa của cached input và uncached input, cách các tier rate limit thực sự hoạt động và những chi phí bổ sung như web search mà mọi người thường bỏ sót khi lập ngân sách.
Vẫn chưa biết nên đọc gì tiếp theo?
Quay lại trung tâm hướng dẫn để duyệt các bài so sánh model, hướng dẫn cài đặt và trang lập kế hoạch phần cứng.