
Gemma-4-Leitfäden
Kimi K2.6 Review: Benchmarks, Preise, API und ob sich der Einsatz lohnt

Update 14. Juni 2026: Kimi listet inzwischen K2.7 Code als neueres Coding-Modell. Globale Preise: K2.6 $0.16 Cache-Hit / $0.95 Input / $4.00 Output pro MTok; K2.7 Code $0.19 / $0.95 / $4.00. Prüfen Sie lokale Abrechnung, Rate Limits und Tool-Preise im Live-Console.
Kimi K2.6 Review: Benchmarks, Preise, API und ob sich der Einsatz lohnt
Moonshot AI veröffentlichte Kimi K2.6 am 20. April 2026 — ihr bislang leistungsfähigstes Open-Weight-Modell, klar positioniert als Coding- und Agent-Flaggschiff. Weniger als zwei Monate zuvor war bereits K2.5 erschienen, das unter offenen Modellen bei Long-Context-Reasoning vorne lag. K2.6 entwickelt diese Linie weiter, aber in eine spezifische Richtung: nicht nur Benchmark-Spitzenwerte, sondern dauerhafte autonome Ausführung.
Dieses Review beantwortet drei Fragen: Was ist K2.6 wirklich, worin ist es tatsächlich gut, und sollten Sie es heute ausprobieren?

Kurzantwort
- Release-Datum: 20. April 2026.
- Verfügbar über:
kimi.com, die Kimi-App, die Moonshot-API und die Kimi Code CLI. Offene Gewichte auf Hugging Face untermoonshotai/Kimi-K2.6. - Architektur: Mixture-of-Experts, etwa 1T Gesamtparameter, etwa 32B aktivierte Parameter pro Token, 256K Kontextfenster, native Vision/Video über den MoonViT-Encoder, Modified-MIT-Lizenz.
- Besonders stark bei: lang laufendem Coding, agentischer Tool-Nutzung, Multi-Agent-Orchestrierung („Agent Swarm“) und Frontend-Generierung aus Prompts.
- Weniger ideal für: reine Mathe-Olympiaden-Reasoning-Aufgaben, ultrakurze Low-Latency-Chats und Workflows, bei denen Kostenberechenbarkeit wichtiger ist als Spitzenleistung.
- Urteil: Wenn Sie Coding-Agenten oder lang laufende autonome Workflows bauen, verdient K2.6 einen echten Evaluationsslot. Für einen günstigen Chatbot ist es überdimensioniert.
Was Kimi K2.6 eigentlich ist
Moonshots eigene Einordnung: Kimi K2.6 ist ein Open-Source-, nativ multimodales, agentisches Modell, das vier Fähigkeiten nach vorn treiben soll — lang laufendes Coding, coding-getriebenes Design, proaktive autonome Ausführung und swarm-basierte Aufgabenorchestrierung.
Die technischen Eckdaten:
- 1 Billion Gesamtparameter, 32 Milliarden aktiv pro Token (MoE).
- 256K Kontextfenster (exakt 262.144 Tokens auf der API-Preiseseite).
- 384 geroutete Experten mit 8 aktiven + 1 gemeinsamem Experten pro Token.
- MoonViT-Vision-Encoder mit 400M Parametern aus K2.5, jetzt mit verbessertem Training.
- Text-, Bild- und Videoeingabe (Video ist als experimentell markiert und nur auf der offiziellen API voll abgesichert).
- Thinking- und Instant-Modus (Thinking ist Standard).
- Modified MIT — für die meisten Einsätze frei nutzbar, mit Attributionsklausel für sehr große Deployments.
Das Modell ist zuerst ein Coding- und Agent-Modell und erst danach ein Chat-Modell. Architektur, Feature-Prioritäten und Marketing zeigen alle in dieselbe Richtung.
Was sich von K2.5 zu K2.6 geändert hat
Zwischen K2.5 (Januar 2026) und K2.6 (April 2026) liegen weniger als drei Monate. Für ein Modell dieser Größe ist das ein schneller Zyklus. Die Verbesserungen konzentrieren sich auf drei Bereiche.
Zuverlässigkeit bei lang laufendem Coding. Moonshots Vorzeige-Demos drehen sich um Ausdauer: K2.6 optimierte lokal auf einem Mac die Inferenz von Qwen3.5-0.8B in Zig über mehr als 12 Stunden und 4.000+ Tool-Calls und endete ungefähr 20 % schneller als LM Studio. Eine zweite Demo zeigt eine 13-stündige Refaktorierung von exchange-core, einer acht Jahre alten Open-Source-Matching-Engine, über 12 Optimierungsrunden hinweg mit etwa 185 % mehr mittlerem Durchsatz. Das sind Selbstangaben und eher Fähigkeitsobergrenzen als Garantien, aber sie deuten klar darauf hin, dass Langzeitstabilität verbessert wurde.
Agent Swarm skaliert stärker. Wo K2.5 grob 100 Sub-Agenten über 1.500 Schritte koordinierte, skaliert K2.6 laut Moonshot auf 300 Sub-Agenten über 4.000 koordinierte Schritte. K2.6 übernimmt die Koordination, verteilt Aufgaben nach Fähigkeitsprofilen, erkennt Stalls und erzeugt Subtasks bei Fehlern neu. Neu ist außerdem Claw Groups (Research Preview), ein Framework, in dem heterogene Agenten von beliebigen Geräten und mit beliebigen Modellen in einem gemeinsamen Arbeitsraum agieren können.
Frontend- und einfaches Full-Stack-Generating. Moonshots Pitch „coding-driven design“ umfasst komplette Websites aus natürlicher Sprache, den Einsatz von Bild- und Videogeneratoren für konsistente Visuals sowie einfache Full-Stack-Aufgaben wie Signup, Datenbankoperationen und Session-Management.
Besseres Instruction Following. Weniger spektakulär, aber für den Alltag oft wichtiger: Unabhängige Beobachter heben wiederholt hervor, dass K2.6 Anweisungen sauberer befolgt als K2.5.
Kimi K2.6 Benchmark-Snapshot
Alle Zahlen stammen aus Moonshots eigenen Evaluationen. Sie sind nützlich für die Einordnung, aber keine unabhängige Schlussabrechnung.
Agentisch
- Humanity's Last Exam (HLE-Full) mit Tools: 54.0
- BrowseComp: 83.2
- DeepSearchQA (F1): 92.5
- Toolathlon: 50.0
Coding
- SWE-Bench Pro: 58.6
- SWE-Bench Verified: 80.2
- SWE-Bench Multilingual: 76.7
- LiveCodeBench v6: 89.6
- Terminal-Bench 2.0 (Terminus-2-Harness): 66.7
Vision
- Charxiv mit Python: 86.7
- Math Vision mit Python: 93.2
- V*: 96.9
Die vernünftige Lesart: K2.6 ist wirklich konkurrenzfähig zu Frontier-Closed-Source-Modellen bei Coding- und Agent-Benchmarks. Bei reinen Reasoning-Benchmarks wie AIME-artiger Mathematik oder GPQA-Diamond haben stärker auf Reasoning vortrainierte Modelle weiterhin Vorteile. Die Wahl des Harnesses beeinflusst Agent-Scores spürbar, daher können unabhängige Leaderboards etwas anders ausfallen.
Wie gut ist Kimi K2.6 fürs Coding?
Gute Einsatzfelder:
- Komplexes, mehrstufiges Coding, das Codebasen lesen, Änderungen planen, Dateien editieren, Tests ausführen und iterieren umfasst.
- Frontend-Generierung aus natürlicher Sprache oder visuellen Vorlagen.
- Agentisches Coding über CLIs wie Claude Code, Codex, OpenCode, OpenClaw und Kimi Code.
- Long-Context-Arbeit mit mittelgroßen Codebasen in einem einzigen Prompt.
- Nicht-englische Kommentare und Dokumentation, insbesondere Chinesisch.
Weniger passende Einsatzfelder:
- Einfache Funktionsvervollständigung, bei der ein kleineres, schnelleres Modell reicht.
- Workloads mit streng planbaren Fixkosten. K2.6 belohnt Caching und bestraft lange Reasoning-Spuren.
- Chats mit harter Latenzanforderung. Thinking ist standardmäßig aktiv und erhöht die Antwortzeit.
Ein kurzer Fit-Check:
| Workload | K2.6-Fit |
|---|---|
| Mehrstündiger autonomer Coding-Agent | Exzellent |
| Copilot-artiges Autocomplete | Overkill |
| Vision-to-Code aus Mockups | Stark |
| Langdokument-Analyse | Stark |
| Echtzeit-Chat-Widget | Schwach (Latenz) |
| Mathe-Wettbewerbsaufgaben | Gut, aber nicht Spitze |
| Datenpipeline mit identischen Prompts | Exzellent (Caching) |
API-, Preis- und Deployment-Optionen
K2.6 ist über mehrere Kanäle verfügbar, jeweils mit eigenen Trade-offs.
Moonshot API. OpenAI-kompatibel unter https://api.moonshot.ai/v1. Aktuelle globale Preise: K2.6 mit gecachter Eingabe $0.16 / 1M Tokens, ungecachter Eingabe $0.95 / 1M Tokens und Ausgabe $4.00 / 1M Tokens; K2.7 Code liegt bei $0.19 / $0.95 / $4.00. Rate Limits hängen vom Konto und der aktuellen Plattformrichtlinie ab, daher vor Produktionslasten die Live-Konsole prüfen. Die integrierte Websuche kann separat berechnet werden und fügt im nächsten Request zusätzliche Eingabetokens hinzu.
Hugging Face. Offene Gewichte unter moonshotai/Kimi-K2.6 mit Modified-MIT-Lizenz. Die offizielle Deploy-Anleitung empfiehlt vLLM, SGLang und KTransformers. Das Model Card deckt Multimodalität, Tool-Calling und den Umgang mit reasoning_content über Agent-Turns hinweg ab.
Ollama. Offizieller Library-Eintrag kimi-k2.6:cloud — ein cloudgeroutetes Modell, keine lokalen Gewichte.
Kimi Code. Moonshots eigener Coding-Agent im Terminal, für Abonnenten durch K2.6 angetrieben.
kimi.com und Kimi App. Consumer-Oberflächen mit eigenen Gratis- und Bezahltarifen.
Für die meisten Teams lautet die Entscheidung: Moonshot-API für Produktion, Ollama Cloud für schnelle Experimente, Hugging Face + vLLM/SGLang für ernsthaftes Self-Hosting mit echtem GPU-Budget.
Wer Kimi K2.6 nutzen sollte
- Agent-Entwickler. Wenn Ihr Produkt hunderte Tool-Calls verkettet, ist K2.6 genau für diese Form gebaut.
- Nutzer von Coding-Tools. Integrationen mit Claude Code, Codex, OpenCode, OpenClaw und Kimi Code sind direkt vorhanden.
- Vision-to-Code-Workflows. Der native MoonViT-Encoder erlaubt Screenshot-zu-Code und Image-zu-UI ohne separates Vision-Modell.
- Teams mit langen Dokumentpipelines. 256K Kontext plus aggressives Caching machen RAG- und Codebase-Workflows wirtschaftlich, wenn Prompts sauber strukturiert sind.
- Chinesische oder bilinguale Teams. Kimi bleibt in Chinesisch ein realer Vorteil.
Wer es eher überspringen sollte
- Teams, die nur die billigsten API-Tokens suchen.
- Produkte mit fixem, text-only Kostenprofil.
- Workflows mit harter Trennung zwischen Cloud und On-Prem, wenn kein Self-Hosting-Budget vorhanden ist.
- Teams ohne Zeit, Thinking-Modus, Tool-Calling und Caching sauber zu konfigurieren.
Endurteil
Kimi K2.6 ist eines der ernsthaftesten Open-Weight-Releases des Jahres 2026. Nach Moonshots eigenen Zahlen ist es bei Coding- und Agent-Benchmarks, die für autonome Workflows relevant sind, mit GPT-5.4 und Claude Opus 4.6 konkurrenzfähig oder ihnen voraus — und bleibt dabei offen gewichtet und unter einer weitgehend permissiven Lizenz. Die Langläufer-Demos sind ungewöhnlich konkret für einen Launch, was Vertrauen schafft, dass die Fähigkeit nicht nur benchmarkoptimiert ist.
Die ehrlichen Einschränkungen: Die Vergleiche sind selbst berichtet, unabhängige Harnesses verschieben die Zahlen, und die Alltagssicherheit eines 12-Stunden-Laufs hängt stark von Ihrer konkreten Aufgabe ab. Preislich ist K2.6 vernünftig, belohnt aber bewusstes Prompt-Design statt casual Nutzung.
Wenn Sie 2026 um Coding-Agenten oder lang laufende autonome Workflows herum bauen, verdient K2.6 eine echte Evaluation und nicht nur einen kurzen Blick. Als Nächstes können Sie einen API-Schlüssel holen (siehe unseren Preisleitfaden), den Ollama-Guide für einen schnellen Test nutzen oder über den Hugging-Face-Leitfaden in Self-Hosting mit vLLM und SGLang einsteigen.
FAQ
Was ist Kimi K2.6?
Kimi K2.6 ist Moonshot AIs Open-Weight-, nativ multimodales Agent-Modell vom 20. April 2026. Es ist ein MoE-Modell mit rund 1T Parametern, etwa 32B aktiven Parametern, 256K Kontext und nativer Text-, Bild- und Videoeingabe.
Ist Kimi K2.6 gut fürs Coding?
Nach Moonshots eigenen Benchmarks ja: SWE-Bench Pro 58.6, SWE-Bench Verified 80.2 und LiveCodeBench v6 89.6. Es glänzt besonders bei mehrstufigen, dateiübergreifenden Aufgaben und Agent-Loops. Für simples Autocomplete ist es meist zu schwergewichtig.
Unterstützt Kimi K2.6 Bilder und Video?
Ja. Bilder werden überall unterstützt, wo K2.6 angeboten wird. Video wird auf der offiziellen Moonshot-API unterstützt und für Third-Party-Deployments als experimentell markiert.
Hat Kimi K2.6 eine API?
Ja, unter https://api.moonshot.ai/v1. Sie ist OpenAI-kompatibel; Sie ändern im OpenAI-SDK nur Base-URL und Schlüssel.
Wie viel kostet Kimi K2.6?
Offizielle Preise: gecachte Eingabe $0.16 / 1M Tokens, ungecachte Eingabe $0.95 / 1M Tokens, Ausgabe $4.00 / 1M Tokens. Die integrierte Websuche kostet aktueller Tools-Preis pro Aufruf plus Ergebnistokens.
Kann man Kimi K2.6 in Ollama nutzen?
Ja, über kimi-k2.6:cloud in der offiziellen Ollama-Library. Es handelt sich dabei um ein Cloud-Modell, nicht um lokale Gewichte.
Ist Kimi K2.6 Open Source?
Die Gewichte werden auf Hugging Face unter einer Modified-MIT-Lizenz veröffentlicht. Für fast alle Teams ist sie praktisch permissiv; eine sichtbare Attributionsklausel greift nur bei sehr großen Deployments.
Verwandte Leitfäden
Gehen Sie im Gemma-4-Cluster mit dem nächsten Leitfaden weiter, der zu Ihrer aktuellen Entscheidung passt.

Kimi K3: Moonshot AIs 2,8T Open-Weight-Modell erklärt
Moonshot AIs Kimi K3 erschien am 16. Juli 2026 als 2,8-Billionen-Parameter Open-Weight-Modell, das Claude Opus 4.8 in mehreren Benchmarks schlägt. Hier erfahren Sie, was es wirklich ist, was noch fehlt und wie Sie es heute testen können.
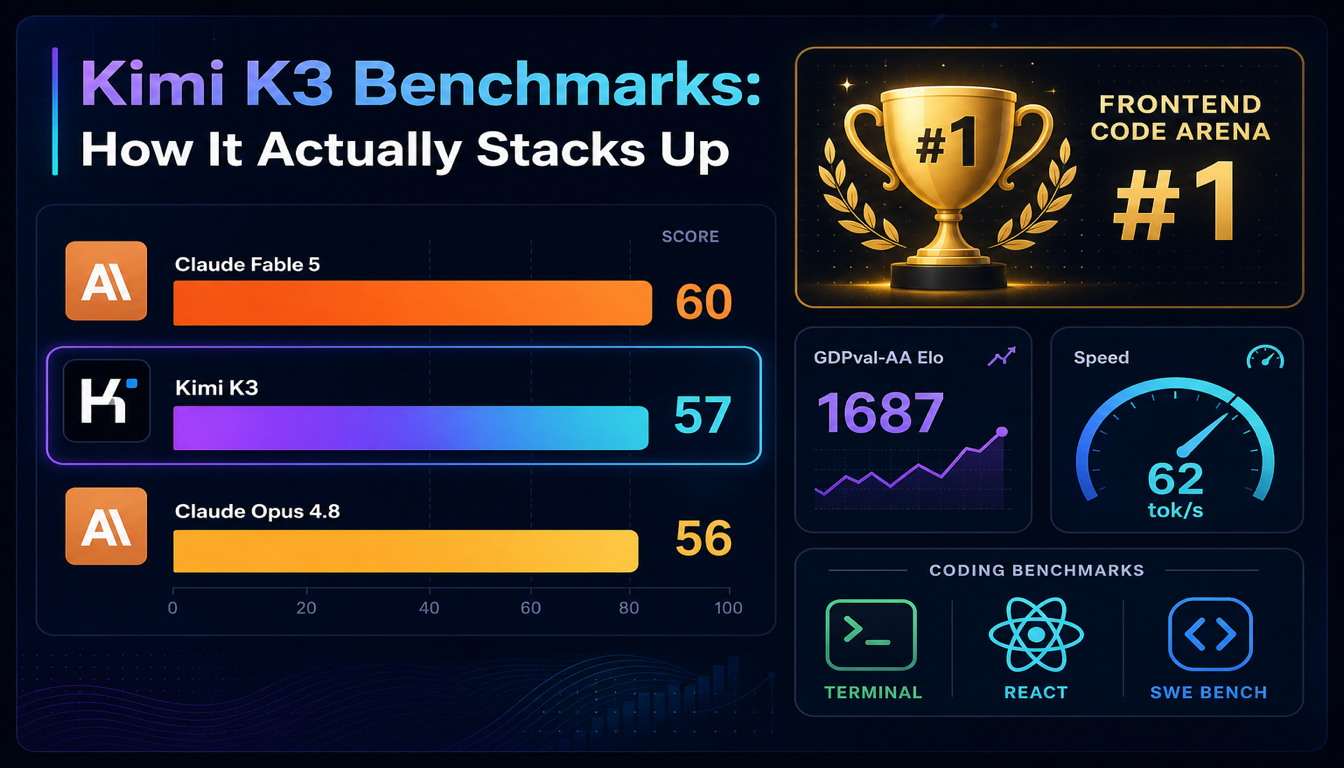
Kimi K3 Benchmarks: Wie es wirklich abschneidet
Kimi K3 erreichte #1 in LMArenas Frontend Code Arena und schlug Claude Opus 4.8 im Artificial Analysis Intelligence Index innerhalb eines Tages nach dem Launch. Hier, was die Zahlen wirklich sagen — und wo sie nicht die ganze Geschichte erzählen.

Kimi K2.6 API-Schlüssel und Preise: Offizielle Kosten, Rate Limits und Web-Suchgebühren
Die offiziellen Token-Preise für Kimi K2.6, was gecachte und ungecachte Eingaben bedeuten, wie die Rate-Limit-Stufen wirklich funktionieren und welche Zusatzkosten – etwa Websuche – beim Budgetieren oft übersehen werden.
Sie wissen noch nicht, was Sie als Nächstes lesen sollen?
Gehen Sie zurück zum Leitfaden-Hub, um Modellvergleiche, Setup-Anleitungen und Seiten zur Hardware-Planung zu durchsuchen.