
Guias do Gemma 4
Review do Kimi K2.6: Benchmarks, Preços, API e se Vale a Pena Usar

Atualização de 14 de junho de 2026: A Kimi agora lista o K2.7 Code como modelo de coding mais recente. Preços globais: K2.6 $0.16 cache hit / $0.95 input / $4.00 output por MTok; K2.7 Code $0.19 / $0.95 / $4.00. Confira cobrança local, rate limits e preços de ferramentas no console ao vivo.
Review do Kimi K2.6: Benchmarks, Preços, API e se Vale a Pena Usar
A Moonshot AI lançou o Kimi K2.6 em 20 de abril de 2026 — o modelo open-weight mais capaz da empresa até agora, posicionado como potência para coding e agentes. Menos de dois meses antes, o K2.5 já ocupava o topo entre modelos open-weight em raciocínio com contexto longo. O K2.6 leva essa linha adiante, mas em uma direção bem específica: não apenas vencer benchmarks, e sim sustentar execução autônoma por muito tempo.
Este review responde a três perguntas: o que o K2.6 realmente é, no que ele é de fato bom e se você deveria testá-lo hoje.

Resposta rápida
- Data de lançamento: 20 de abril de 2026.
- Disponível em:
kimi.com, app Kimi, API da Moonshot e Kimi Code CLI. Pesos abertos no Hugging Face emmoonshotai/Kimi-K2.6. - Arquitetura: Mixture-of-Experts, ~1T de parâmetros totais, ~32B ativados por token, janela de contexto de 256K, visão/vídeo nativos via encoder MoonViT, licença Modified MIT.
- Melhor em: coding de longo horizonte, uso agentic de ferramentas, orquestração multiagente (“Agent Swarm”) e geração de front-end a partir de prompts.
- Pior encaixe para: raciocínio matemático puro de competição, chats curtíssimos de baixíssima latência e workflows em que previsibilidade de custo importa mais do que pico de capacidade.
- Veredito: se você constrói coding agents ou workflows autônomos longos, o K2.6 merece uma avaliação séria. Se você só quer um modelo de chat barato, ele é mais do que o necessário.
O que o Kimi K2.6 realmente é
No enquadramento da própria Moonshot, o Kimi K2.6 é um modelo open-source, nativamente multimodal e agentic, voltado a quatro capacidades: coding de longo horizonte, design orientado por código, execução autônoma proativa e orquestração de tarefas baseada em swarm.
Em termos técnicos:
- 1 trilhão de parâmetros totais, 32 bilhões ativados por token (MoE).
- 256K de contexto (262.144 tokens exatamente na página de preços da API).
- 384 experts roteados, com 8 ativos + 1 compartilhado por token.
- MoonViT, encoder de visão com 400M de parâmetros herdado do K2.5 e refinado.
- Entrada de texto, imagem e vídeo (vídeo é marcado como experimental fora da API oficial).
- Modos Thinking e Instant (Thinking é o padrão).
- Licença Modified MIT, livre para quase todos os usos, com cláusula de atribuição para deploys muito grandes.
É um modelo de coding e agentes primeiro, e um modelo de chat em segundo plano. A arquitetura, os recursos e o posicionamento contam a mesma história.
O que mudou do K2.5 para o K2.6
O intervalo entre o K2.5 (janeiro de 2026) e o K2.6 (abril de 2026) foi de menos de três meses. Para um modelo desse porte, é um ciclo rápido. As melhorias se concentram em três áreas.
Confiabilidade em coding de longa duração. As demos principais da Moonshot são sobre resistência: o K2.6 otimizando inferência local do Qwen3.5-0.8B em um Mac usando Zig por mais de 12 horas e 4.000+ tool calls, terminando cerca de 20% mais rápido que o LM Studio; e uma refatoração autônoma de 13 horas em exchange-core, com cerca de 185% de ganho em throughput médio. São números auto-relatados, então trate-os como teto de capacidade, não garantia. Ainda assim, apontam que o modelo melhorou justamente onde agentes longos costumam quebrar.
Agent Swarm mais escalável. Onde o K2.5 coordenava cerca de 100 subagentes em 1.500 passos, o K2.6 escala para 300 subagentes em 4.000 passos coordenados. O próprio K2.6 atua como coordenador, delegando tarefas por perfil, detectando bloqueios e regenerando subtarefas quando algo falha. O lançamento também inclui Claw Groups, uma prévia de pesquisa para cooperação entre agentes heterogêneos rodando em diferentes dispositivos e modelos.
Geração de front-end e full stack básico. A proposta de “coding-driven design” inclui montar sites completos a partir de prompts, usar ferramentas de geração de imagem e vídeo para manter consistência visual e lidar com tarefas básicas de full stack, como cadastro, operações de banco e sessão.
Melhor seguimento de instruções. É menos chamativo, mas revisores independentes têm notado que o K2.6 segue instruções melhor do que o K2.5 no uso do dia a dia.
Snapshot de benchmarks do Kimi K2.6
Todos os números abaixo vêm das avaliações da própria Moonshot. Servem para orientação, não como veredito independente definitivo.
Agentic
- Humanity's Last Exam (HLE-Full) com tools: 54.0
- BrowseComp: 83.2
- DeepSearchQA (F1): 92.5
- Toolathlon: 50.0
Coding
- SWE-Bench Pro: 58.6
- SWE-Bench Verified: 80.2
- SWE-Bench Multilingual: 76.7
- LiveCodeBench v6: 89.6
- Terminal-Bench 2.0: 66.7
Visão
- Charxiv com Python: 86.7
- Math Vision com Python: 93.2
- V*: 96.9
Leitura honesta: o K2.6 é realmente competitivo com modelos frontier fechados em benchmarks de coding e agentes. Já em provas de raciocínio puro, como matemática estilo AIME ou GPQA-Diamond, modelos mais focados em reasoning ainda podem levar vantagem. Em benchmarks agentic, o harness e as ferramentas disponíveis mudam bastante o resultado, então placares independentes podem diferir alguns pontos.
Quão bom o Kimi K2.6 é para coding?
Onde ele encaixa bem:
- Coding complexo e multi-etapas, com leitura de codebase, planejamento, edição em vários arquivos, testes e iteração.
- Geração de front-end a partir de prompts naturais ou visuais.
- Coding agentic via CLI, como Claude Code, Codex, OpenCode, OpenClaw e Kimi Code.
- Trabalho com contexto longo, inclusive carregando codebases medianas na janela de 256K.
- Comentários e documentação não ingleses, especialmente em chinês.
Onde ele encaixa pior:
- Autocompletar simples, onde um modelo menor e mais barato já resolve.
- Workloads que exigem custo previsível e fixo.
- Chat de latência muito baixa. O modo Thinking vem ligado por padrão e adiciona tokens de raciocínio em toda resposta.
Atalho rápido:
| Workload | Fit do K2.6 |
|---|---|
| Agente autônomo de coding por horas | Excelente |
| Autocomplete estilo Copilot | Exagero |
| Mockup → UI funcional | Forte |
| Análise de documentos longos | Forte |
| Widget de chat em tempo real | Fraco (latência) |
| Resolução de matemática competitiva | Bom, mas não topo absoluto |
| Pipeline com prompts idênticos | Excelente (cache) |
API, preços e opções de deploy
O K2.6 chega por vários canais, cada um com um trade-off diferente.
API da Moonshot. Compatível com OpenAI em https://api.moonshot.ai/v1. Preços globais atuais: K2.6 com input em cache $0.16 / 1M tokens, input sem cache $0.95 / 1M e output $4.00 / 1M; K2.7 Code em $0.19 / $0.95 / $4.00. Os rate limits dependem da conta e da política atual da plataforma, então confira o console ao vivo antes de cargas de produção. A busca na web integrada pode ser cobrada separadamente e também adiciona tokens de input ao próximo request.
Hugging Face. Pesos abertos em moonshotai/Kimi-K2.6 sob licença Modified MIT. O guia oficial recomenda vLLM, SGLang e KTransformers. O model card também cobre multimodalidade, tool calling e preservação de reasoning_content.
Ollama. Entrada oficial kimi-k2.6:cloud — é um modelo roteado pela nuvem, não pesos locais.
Kimi Code. Agente de coding em terminal da própria Moonshot.
kimi.com e app Kimi. Superfícies de chat e agentes para consumidores, com seus próprios planos.
Para a maioria das equipes, a decisão fica assim: API Moonshot para produção, Ollama cloud para testes rápidos, Hugging Face + vLLM/SGLang para self-hosting sério.
Quem deveria usar o Kimi K2.6
- Desenvolvedores de agentes. Se seu produto encadeia centenas de tool calls, o K2.6 foi desenhado para esse formato.
- Usuários de ferramentas de coding. Claude Code, Codex, OpenCode, OpenClaw e Kimi Code têm integração direta.
- Workflows vision-to-code. O encoder MoonViT permite screenshot-to-code sem um modelo de visão separado.
- Times com pipelines de documentos longos. 256K de contexto + cache agressivo funcionam bem em RAG e codebases inteiras.
- Times bilíngues ou focados em chinês. O Kimi continua forte nesse ponto.
Quem pode pular
- Times otimizando apenas pelo token de API mais barato.
- Produtos que precisam de custo fixo e previsível em texto puro.
- Workflows com exigência rígida de separação entre nuvem e on-prem, sem orçamento para self-host.
- Times sem tempo para ajustar Thinking mode, tool calling e padrões de cache.
Veredito final
O Kimi K2.6 é um dos lançamentos open-weight mais sérios de 2026. Pelos números da própria Moonshot, ele compete com ou supera GPT-5.4 e Claude Opus 4.6 nos benchmarks de coding e agentes mais relevantes para workflows autônomos, e faz isso mantendo pesos abertos e licença amplamente permissiva. As demos de longa duração são específicas o bastante para sugerir capacidade real, não só tuning para benchmark.
As ressalvas honestas: os comparativos são auto-relatados, harnesses independentes vão deslocar os números e a confiabilidade de uma execução de 12 horas depende da tarefa concreta. O preço é razoável, mas recompensa design cuidadoso de prompt e caching, não uso casual.
Se você está construindo em torno de coding agents ou workflows autônomos de longa duração em 2026, o K2.6 merece avaliação séria. Os próximos passos naturais são o guia de preços da API, o guia do Ollama e o guia do Hugging Face.
FAQ
O que é o Kimi K2.6?
O Kimi K2.6 é o modelo open-weight e nativamente multimodal da Moonshot AI, lançado em 20 de abril de 2026. É um modelo MoE com ~1T de parâmetros totais, ~32B ativos, janela de contexto de 256K e entrada nativa de texto/imagem/vídeo.
O Kimi K2.6 é bom para coding?
Nos benchmarks reportados pela Moonshot, sim: SWE-Bench Pro 58.6, SWE-Bench Verified 80.2 e LiveCodeBench v6 89.6. Ele brilha em tarefas multi-etapas e loops de agentes. Para autocomplete simples, é excesso.
O Kimi K2.6 suporta imagem e vídeo?
Sim. Imagens funcionam em todos os principais caminhos. Vídeo é suportado na API oficial da Moonshot e marcado como experimental em deploys de terceiros.
Ele tem API?
Sim, em https://api.moonshot.ai/v1. É compatível com OpenAI, então basta trocar base URL e chave no SDK.
Quanto custa?
Preços oficiais: input em cache $0.16 / 1M tokens, input sem cache $0.95 / 1M tokens, output $4.00 / 1M tokens. A web search integrada custa preço atual das ferramentas por chamada, mais os tokens dos resultados.
Dá para usar no Ollama?
Sim, via kimi-k2.6:cloud na biblioteca oficial do Ollama. Trata-se de um modelo em nuvem, não local.
O Kimi K2.6 é open source?
Os pesos são publicados no Hugging Face sob licença Modified MIT. Para quase todas as equipes, a licença é efetivamente permissiva, com cláusula extra de atribuição apenas para deploys muito grandes.
Guias relacionados
Continue no cluster do Gemma 4 com o proximo guia que combina com a decisao que voce esta tomando agora.

Kimi K3: O Modelo Open-Weight de 2,8T da Moonshot AI Explicado
O Kimi K3 da Moonshot AI foi lançado em 16 de julho de 2026 como um modelo open-weight de 2,8 trilhões de parâmetros que supera o Claude Opus 4.8 em vários benchmarks. Aqui está o que ele realmente é, o que ainda falta e como testá-lo hoje.
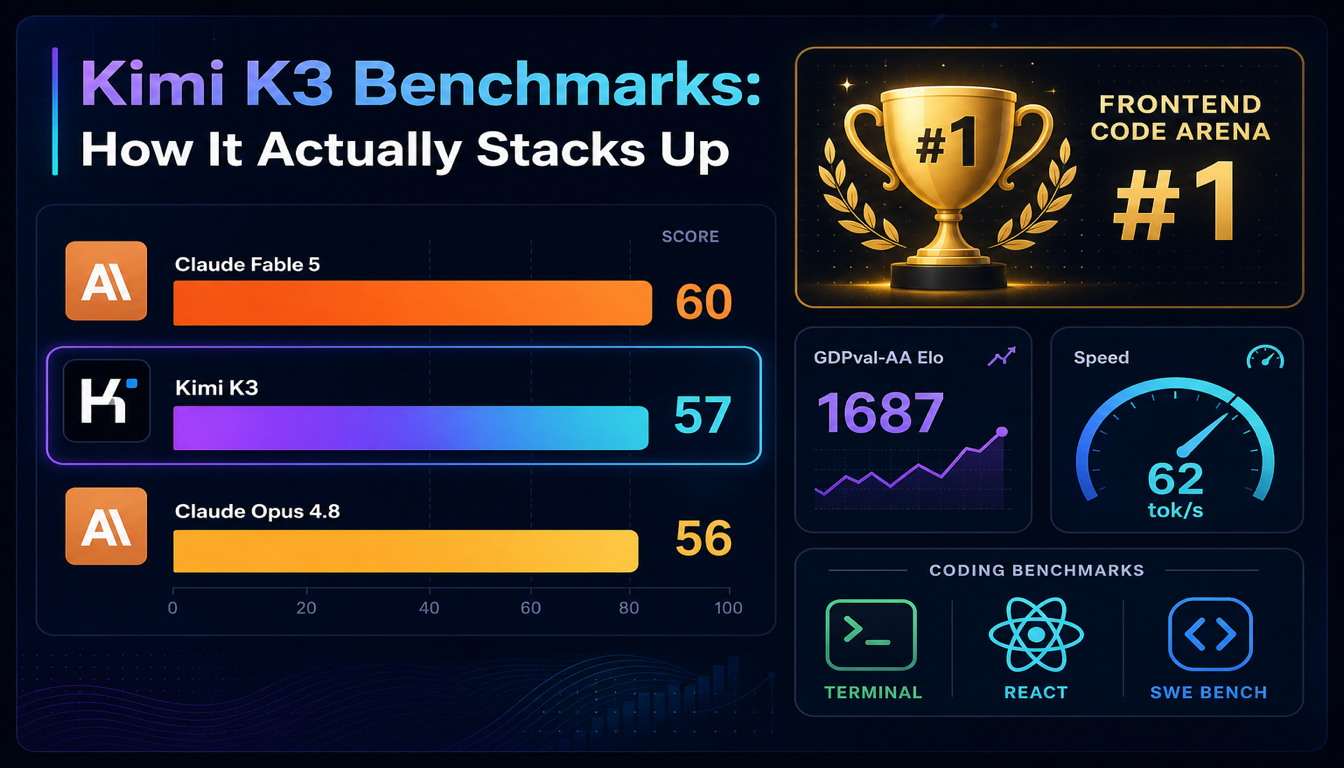
Benchmarks do Kimi K3: Como Ele Realmente Se Compara
O Kimi K3 chegou ao #1 no Frontend Code Arena da LMArena e superou o Claude Opus 4.8 no Artificial Analysis Intelligence Index em menos de um dia após o lançamento. Veja o que os números realmente dizem — e onde não contam a história toda.

Chave de API e Preços do Kimi K2.6: Custos Oficiais, Limites de Taxa e Taxas de Busca na Web
Os preços oficiais por token do Kimi K2.6, o que significam cached input e uncached input, como os níveis de rate limit funcionam na prática e quais custos extras — como busca na web — as pessoas esquecem ao fazer orçamento.
Ainda decidindo o que ler depois?
Volte para o hub de guias para navegar por comparacoes de modelos, tutoriais de configuracao e paginas de planejamento de hardware.