

重点推荐
Gemma 4 E2B vs E4B:小模型到底该选谁?
•约 6 分钟
一篇实用的 Gemma 4 E2B vs E4B 对比指南,聚焦真实性能差距、显存需求,以及谁才是更值得默认先试的小模型。
gemma 4e2be4b模型对比本地大模型显存
Gemma 4 指南
围绕本地部署、硬件要求和模型选型,系统整理 Gemma 4 的实用内容。
如果你只打算先读几篇,那就优先从模型选型、硬件规划,以及最常见的部署和对比问题开始。
一篇实用的 Gemma 4 E2B vs E4B 对比指南,聚焦真实性能差距、显存需求,以及谁才是更值得默认先试的小模型。

一篇实用的 Gemma 4 26B vs 31B 对比指南,帮你判断 MoE 甜点位和最强 dense 模型之间该怎么选。
一份实用的 Gemma 4 VRAM 计算器 / model chooser,基于公开内存数据,帮你在下载前先做对型号选择。
适合正在决定应该选哪个 Gemma 4 版本,或者要不要和其他模型家族做对比的人。

E 代表 effective(有效参数),A 代表 active(激活参数)。两者是完全不同的架构。本文告诉你如何根据自己的机器选对模型。

对大多数本地配置来说,Q4_K_M 是正确的起点。Q8 在内存不紧张时对多步推理和长代码任务有帮助。还有一个 QAT 选项会彻底改变这道计算题。

Kimi K2.6 和 GLM-5.1 是 2026 年 4 月的重要 open-weight 发布,但新的评估应该把 Kimi K2.7 Code 和 GLM-5.2 一起纳入。

彻底解读 Gemma 4 更新后的五模型家族,横向对比主要版本,下载前帮你选对适合自己硬件的模型。

Gemma 4 vs Qwen 不是一句话能下结论的问题,真正重要的是哪个家族更适合你的栈、硬件和部署路径。
围绕 Ollama、LM Studio、llama.cpp、Google AI Studio 和相关工作流的实际部署指南。

2026年GLM 5.2完整定价指南:API按Token计费详情、GLM Coding Plan订阅套餐(Lite/Pro/Max/Team)、OpenRouter价格及国内免费使用方案。

GLM 5.2 于2026年6月13日正式发布,744B MoE参数、100万Token上下文窗口、MIT开源协议,在多项长任务编码榜单上直追闭源前沿模型,API价格仅为GPT-5.5的约六分之一。本文带你全面了解这个模型。

GLM 5.2 基于MIT开源许可证,可免费下载和自部署。同时,Cloudflare Workers AI和z.ai网页版也提供免费体验。本文详细介绍所有免费使用方式,以及何时需要付费。

GLM-5.2 已通过 glm-5.2:cloud 标签在 Ollama 中上线——一条命令即可使用 976K 上下文的编程模型,无需自行管理 744B 参数的本地下载。

LM Studio 的 llama.cpp 和 MLX 引擎在 2026 年 6 月都无法加载 DiffusionGemma。本文解释这些错误的含义、在哪里跟踪,以及实际有效的工具。

标准 llama.cpp 无法运行 DiffusionGemma。支持在 PR #24423 中,该 PR 提供了独立的 llama-diffusion-cli 二进制文件。以下是目前真正可用的方案。

gemma4 和 diffusion-gemma 架构错误有不同的原因和不同的修复方法。把它们当作同一个问题处理只会浪费时间。

Kimi K2.6 与 K2.7 Code 的当前 API 价格、cache hit 的含义、速率限制层级如何影响吞吐,以及做预算前应该核对哪些项目。

开发者需要从 `moonshotai/Kimi-K2.6` model card 中知道的内容:权重里实际包含什么、如何用 vLLM 或 SGLang 部署,以及什么时候应选择 self-host 而不是官方 API。

Kimi K2.6 于 2026 年 4 月 20 日发布,是一个面向 agentic coding 的 open-weight 模型,拥有 256K 上下文、原生图像与视频输入,以及激进的 agent swarm 叙事。这篇文章会拆开哪些是实力,哪些是营销。

一份通过官方 `kimi-k2.6:cloud` 条目在 Ollama 中运行 Kimi K2.6 的实用指南,涵盖设置命令、coding agent 集成,以及 Ollama 云后端对工作流意味着什么。
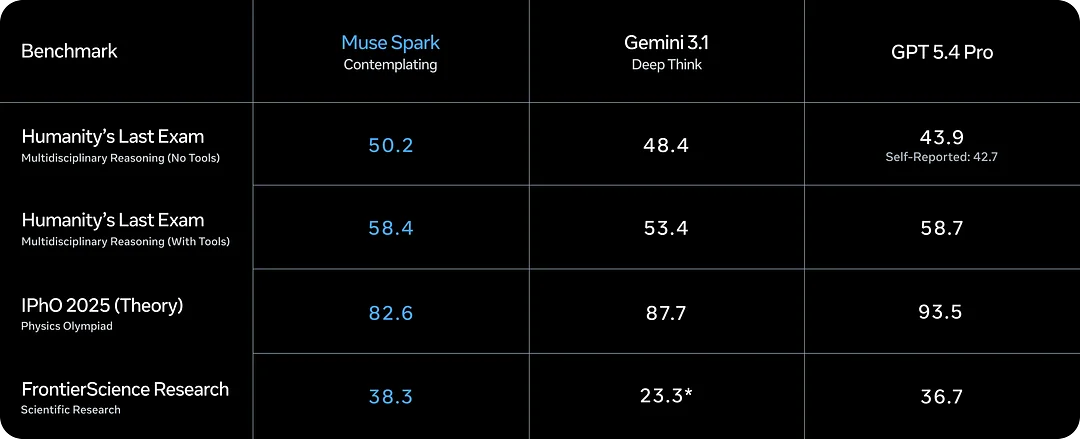
Muse Spark 是 Meta 超级智能实验室发布的全新 AI 模型。本文解析其核心能力、Contemplating 模式、基准成绩以及在落地前需要注意的问题。

直接回答 llama.cpp 是否支持 Gemma 4,并整理官方 GGUF 链接、修复状态与当前最实用的判断方式。

直接回答 LM Studio 是否支持 Gemma 4,并说明当前可用模型、最低内存,以及 LM Studio 路线真正适合什么人。

直接回答 Unsloth 是否支持 Gemma 4,并整理本地运行、微调、导出与大模型注意事项。

一篇聚焦 Gemma 4 26B A4B 显存要求的实用指南,帮你判断 26B 为什么是很多本地用户最值得先试的版本。

一篇聚焦 Gemma 4 31B 显存要求的实用指南,给出公开 GGUF 体积、规划区间和本地部署时真正该怎么判断。

一篇聚焦 Gemma 4 E2B 显存要求的实用指南,帮你判断它什么时候才是值得优先考虑的小模型。

一篇聚焦 Gemma 4 E4B 显存要求的实用指南,帮你判断它为什么是很多本地用户最值得先试的小模型。

如果你想在 iPhone 或 iPad 上离线体验 Gemma 4,这篇文章会帮你快速判断设备适配、模型选择和真实体验。

如果你想把 Gemma 4 作为本地 API 用起来,这篇文章会帮你快速完成服务搭建、验证和工具接入。

从硬件判断、运行时选择到常见报错排查,这篇文章会帮你把 Gemma 4 on Windows 更稳地跑起来。

按这份步骤指南,用 Unsloth 微调 Gemma 4,结合你的硬件选择合适模型,并把结果导出到 Ollama、llama.cpp 或 LM Studio。

如果你正准备本地运行 Gemma 4,这篇 Gemma 4 GGUF 下载文章会帮你从来源选择、量化判断到首轮验证一次理顺。

如果你正在做模型选择,这篇 Gemma 4 评测会帮你快速判断它值不值得投入,以及应该从哪个版本开始。
如果你最近在搜索 what is gemma 4,这篇文章会用最容易上手的方式解释 Gemma 4 AI、版本结构、许可变化和起步路径。

如果你还不确定要不要本地部署 Gemma 4,Google AI Studio 往往是一个更快、更轻的评估入口。

把 Gemma 4 和 Unsloth 放在一起时,真正重要的不是炫技,而是先弄清楚你的目标到底是实验、调优,还是生产。

如果你想用图形界面的方式本地体验 Gemma 4,这篇 LM Studio 指南会帮你避开最常见的错误。

从零到本地跑通 Gemma 4 的最快路径:选对标签、确认硬件、执行正确命令——不在错误的模型上浪费时间。

从硬件配置表到一键复制的构建命令,再到量化方案和多模态配置——让 Gemma 4 在本地跑起来所需的一切都在这里。
帮助你先判断机器是否合适,再决定要不要下载模型,避免第一步就走错。

GLM 5.2 是一个拥有 7440 亿参数的 MoE 模型,基于 MIT 协议开放权重。本文详细介绍在本地运行所需的全部硬件条件。

Mac mini 确实可以运行 Gemma 4,但真正重要的问题是:你打算跑哪个版本,以及你希望得到怎样的体验。
