

추천
Gemma 4 E2B vs E4B: 어떤 소형 모델을 선택해야 할까요?
•6분 읽기
두 소형 모델 중 고민하는 분들을 위한 Gemma 4 E2B vs E4B 실전 가이드로, 실제 벤치마크 차이와 메모리 가이드를 제공합니다.
gemma 4e2be4b모델 비교로컬 LLMvram
Gemma 4 가이드
Gemma 4를 검토하는 사람들을 위한 로컬 설정 워크스루, 하드웨어 요구사항 표, 모델 선택 가이드입니다.
몇 페이지만 먼저 읽을 예정이라면 모델 선택, 하드웨어 계획, 가장 자주 묻는 설정 및 비교 주제부터 살펴보세요.
두 소형 모델 중 고민하는 분들을 위한 Gemma 4 E2B vs E4B 실전 가이드로, 실제 벤치마크 차이와 메모리 가이드를 제공합니다.

MoE 모델의 황금비와 패밀리 내 최강의 Dense 모델 사이에서 고민 중인 분들을 위한 실용적인 Gemma 4 26B vs 31B 비교 가이드입니다.
공식 메모리 수치를 바탕으로 제작된 실용적인 Gemma 4 VRAM 계산기입니다. 다운로드 전에 본인의 하드웨어 사양에 가장 적합한 모델을 선택하세요.
어떤 Gemma 4 경로를 선택할지 결정하는 사람들을 위한 모델 계열 비교 및 버전 선택 가이드입니다.

GLM 5.2는 1M 컨텍스트 창을 가진 오픈웨이트 코딩 거인이고, Gemma 4는 3GB~20GB VRAM에서 동작하는 로컬 친화적 모델 패밀리입니다. 선택 방법을 안내합니다.

E는 effective parameters(유효 파라미터), A는 active parameters(활성 파라미터)의 약자입니다. 완전히 다른 아키텍처입니다. 내 장비에 맞는 모델 선택법을 알아봅니다.

대부분의 로컬 환경에서 Q4_K_M이 올바른 출발점입니다. Q8은 메모리가 여유로울 때 다단계 추론과 긴 코드 작업에 특히 도움됩니다. 계산을 완전히 바꾸는 QAT 옵션도 있습니다.

2026년 중국에서 나온 가장 강력한 open-weight 모델 둘. 2주 간격으로 출시됐고 비슷한 코딩 워크로드를 겨냥하지만, 모달리티, 컨텍스트, 가격 구조는 확실히 다릅니다.

Gemma 4의 네이밍 시스템을 분석하고 네 가지 변체 간의 벤치마크를 비교하여, 다운로드 전에 실제 본인의 하드웨어에 가장 적합한 모델을 찾아보세요.

Gemma 4와 Qwen 중 무엇이 더 나은지에 대한 답은 상황에 따라 다릅니다. 이 가이드는 워크플로우, 하드웨어, 배포 환경 및 생태계 적합성을 기준으로 선택을 도와줍니다.
Ollama, LM Studio, llama.cpp, Google AI Studio 및 관련 Gemma 4 워크플로를 위한 실전 설정 가이드입니다.

2026년 GLM 5.2 가격 완전 가이드: API 토큰 비용, GLM Coding Plan 구독 등급(Lite/Pro/Max/Team), OpenRouter 요금, 무료 접근 방법까지 한눈에 확인하세요.

GLM 5.2는 2026년 6월 13일 출시된 Zhipu AI의 오픈 웨이트 플래그십 모델로, 744B MoE 파라미터, 100만 토큰 컨텍스트 창, MIT 라이선스를 갖추고 GPT-5.5의 약 6분의 1 비용으로 클로즈드 소스 프론티어 모델에 필적하는 성능을 보여줍니다.

GLM 5.2는 MIT 라이선스로 무료 다운로드 및 자체 호스팅이 가능합니다. Cloudflare Workers AI와 z.ai 웹 채팅을 통한 무료 체험도 가능합니다. 이 가이드는 모든 무료 옵션과 유료 전환 시점을 설명합니다.

GLM-5.2는 glm-5.2:cloud 태그를 통해 Ollama에서 사용 가능합니다. 명령 하나로 976K 컨텍스트 코딩 모델을 사용할 수 있으며, 744B 파라미터를 직접 다운로드할 필요가 없습니다.

LM Studio의 llama.cpp와 MLX 엔진 모두 2026년 6월 현재 DiffusionGemma 로드에 실패합니다. 오류가 무엇을 의미하는지, 어디서 추적되는지, 실제로 작동하는 도구는 무엇인지 설명합니다.

DiffusionGemma는 llama.cpp에서 작동하지만, 표준 llama-cli가 아닌 PR #24423의 llama-diffusion-cli 바이너리가 필요합니다. 빌드 또는 다운로드 방법을 안내합니다.

gemma4와 diffusion-gemma 아키텍처 오류는 원인이 다르고 수정 방법도 다릅니다. 같은 방법으로 처리하면 시간만 낭비됩니다.

Kimi K2.6의 공식 토큰 가격, cached input 과 uncached input 의 의미, 레이트 리밋 티어가 실제로 어떻게 작동하는지, 그리고 예산을 잡을 때 놓치기 쉬운 웹 검색 같은 추가 비용까지 설명합니다.

`moonshotai/Kimi-K2.6` 모델 카드에서 개발자가 알아야 할 내용을 정리했습니다. 실제 weights 구성, vLLM/SGLang 배포 방법, 그리고 self-host와 공식 API 중 어떤 선택이 맞는지 설명합니다.

Kimi K2.6는 2026년 4월 20일 공개된 open-weight agentic coding 모델로, 256K 컨텍스트, 네이티브 이미지/비디오 입력, 그리고 강한 agent-swarm 서사를 갖고 있습니다. 이 리뷰는 무엇이 실체이고 무엇이 마케팅인지 가려냅니다.

공식 `kimi-k2.6:cloud` 엔트리를 통해 Ollama에서 Kimi K2.6를 사용하는 실전 가이드입니다. 설정 명령, 코딩 에이전트 연동, 그리고 클라우드 기반 Ollama가 워크플로에 의미하는 바를 다룹니다.
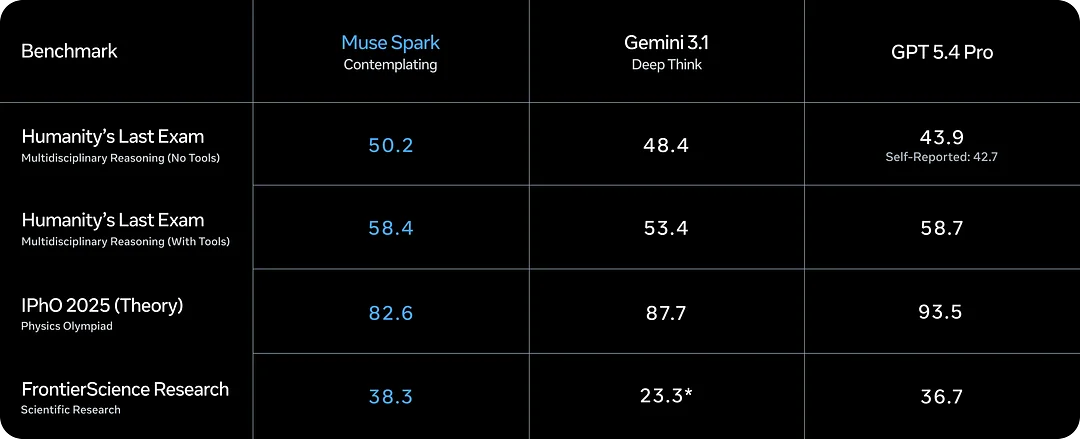
Muse Spark는 Meta Superintelligence Labs에서 출시한 Meta의 새로운 AI 모델입니다. 이 가이드는 핵심 기능, Contemplating 모드, 벤치마크, 도입 전 확인해야 할 사항을 설명합니다.

llama.cpp가 Gemma 4를 지원하는지에 대한 답변과 함께, 공식 GGUF 링크, 현재 지원 상태 및 '지원됨'의 실제 의미를 설명하는 실전 가이드입니다.

LM Studio가 Gemma 4를 지원하는지에 대한 명확한 답변과 함께, 지원 모델 목록, 최소 메모리 사양 및 실질적인 설정 기대치를 다룹니다.

Unsloth가 Gemma 4를 지원하는지에 대한 답변과 함께, 로컬 실행 지원, 파인튜닝 지원 및 모델별 주의 사항을 다루는 실전 가이드입니다.

iOS 설정, 모델 선택, 기기 적합성, 오프라인 사용법 및 예상 성능을 다루는 실용적인 iPhone용 Gemma 4 가이드입니다.

이 Gemma 4 API 가이드를 통해 로컬 OpenAI 호환 엔드포인트를 구축하고, 신속하게 테스트하며, 본인의 워크플로우에 맞는 최적의 런타임을 선택해 보세요.

하드웨어 점검, Ollama와 LM Studio 설치법, 모델 선택 기준부터 Windows 환경에서 흔히 발생하는 문제 해결까지 다루는 실질적인 설정 가이드입니다.

Unsloth로 Gemma 4를 파인튜닝하고, 하드웨어에 맞는 모델을 선택하며, 결과를 Ollama, llama.cpp 또는 LM Studio용으로 내보내는 단계별 과정을 확인하세요.

신뢰할 수 있는 소스를 선택하고, 본인에게 맞는 파일을 골라 다운로드부터 첫 로컬 응답까지 시행착오를 줄이는 데 도움을 주는 Gemma 4 GGUF 다운로드 가이드입니다.

모델 제품군에 대한 이해, 핵심 벤치마크 수치, 그리고 실제 도입 전 고려해야 할 트레이드오프를 확인하여 본인에게 맞는 Gemma 4 모델을 선택하세요.
Gemma 4가 무엇인지 궁금하다면, 이 가이드를 통해 출시 정보, 모델 크기, 컨텍스트 제한, 라이선스 및 시작하기 가장 쉬운 방법들을 확인하세요.

Google AI Studio는 로컬 설정을 하기 전, 호스팅된 Gemma 4의 성능을 가장 빠르게 평가해 볼 수 있는 방법 중 하나입니다.

Unsloth가 Gemma 4 워크플로우에서 어떤 역할을 하는지 이해하고, 본격적인 튜닝 단계로 넘어가기 전에 결정해야 할 사항들을 확인하세요.

모델 선택, 하드웨어 적합성, 첫 실행 워크플로우에 초점을 맞춘 Gemma 4용 실전 LM Studio 가이드입니다.

설명서 없이 즉시 Gemma 4 로컬 구동을 시작하세요. 적절한 태그 선택부터 하드웨어 점검, 명령어 실행까지 시간을 낭비하지 않는 실무 가이드를 제공합니다.

llama.cpp로 Gemma 4 시작하기: 하드웨어에 맞는 GGUF 선택, CUDA/Metal/CPU 지원 빌드, 12B–31B 모델 로컬 실행. 복사-붙여넣기 명령어 포함.
처음부터 잘못된 모델을 내려받지 않도록 도와주는 하드웨어 요구사항 페이지와 기기별 계획 가이드입니다.

GLM 5.2는 MIT 라이선스로 공개된 7,440억 파라미터 MoE 모델입니다. 로컬에서 실행하는 데 필요한 모든 하드웨어 정보를 정리했습니다.

정확한 GGUF 파일 크기, 계획 범위, 그리고 왜 26B 모델이 로컬 환경의 황금비(sweet spot)인지 설명하는 Gemma 4 26B A4B VRAM 요구 사항 가이드입니다.

정확한 GGUF 파일 크기, 계획 범위, 그리고 어떤 하드웨어가 실질적으로 적합한지에 대한 진솔한 조언을 담은 Gemma 4 31B VRAM 요구 사항 가이드입니다.

정확한 파일 크기, 실질적인 계획 범위, 그리고 E2B가 적합한 상황에 대한 진솔한 조언을 담은 Gemma 4 E2B VRAM 요구 사항 가이드입니다.

정확한 파일 크기, 계획 범위, 그리고 노트북급 로컬 AI 환경을 위한 실질적인 조언을 담은 Gemma 4 E4B VRAM 요구 사항 가이드입니다.

Mac mini에서 Gemma 4를 실행할 수 있는지에 대한 진짜 답은 어떤 Gemma 4 모델을 염두에 두고 있으며 어떤 수준의 경험을 기대하느냐에 달려 있습니다.

공식적인 대략적 메모리 수치표와 어떤 모델부터 시도해야 할지에 대한 간단한 조언을 담은 실용적인 Gemma 4 하드웨어 가이드입니다.